A basic design pattern for image recognition
Learn how a design pattern based on convolutional neural networks can be adapted to create a visual graphics generator model for image recognition.
Prior to 2017, most renditions of neural network models were coded in a batch scripting style. As AI researchers and experienced software engineers became increasingly involved in research and design, we started to see a shift in the coding of models that reflected software engineering principles for reuse and design patterns.
A design pattern implies that there is a "best practice" for constructing and coding a model that can be reapplied across a wide range of cases, such as image classification, object detection and tracking, facial recognition, image segmentation, super resolution and style transfer.
The introduction of design patterns also helped advance convolutional neural networks (as well as other network architectures) by aiding other researchers in understanding and reproducing a model's architecture.
A procedural style for reuse was one of the earliest versions of using design patterns for neural network models. Understanding the architecture of the procedural reuse design pattern is crucial if you are going to apply it to any model you are building. Once you see how the parts work, individually and together, you can start working with the code that builds these parts -- code that is available free for downloading. In my new book, Deep Learning Design Patterns, I show how the procedural reuse design pattern makes it easier to reproduce model components by applying it to several formerly state-of-the-art models including VGG, ResNet, ResNeXt, Inception, DenseNet and SqueezeNet. This offers both a deeper understanding of how these models work, as well as practical experience reproducing them.
In this article I'll introduce you to a procedural reuse design pattern based on the idiomatic design pattern for convolutional neural networks (CNNs). Then we'll look at how the design pattern can be retrofitted into an early state-of-the-art CNN model for image recognition: the visual graphics generator (VGG).
CNN macro architecture
Let's start with a quick overview of the structure of a CNN, to help you understand where design patterns can fit into the process.
The macro architecture of a CNN follows the three-component convention consisting of a stem, a learner and a task, as depicted in the following figure.
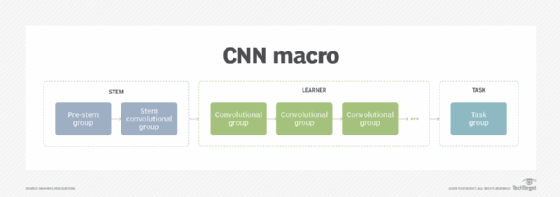
The stem takes the input (an image, for example) and does the initial coarse-level feature extraction. This extraction then becomes the input to the learner component. Sometimes we may add a pre-stem to perform functions in the model that were previously done upstream, like image preprocessing and augmentation.
The learner uses a sequence of convolutional groups to do detailed feature extraction as well as the representational learning from those extracted coarse features. The output from the learner component is referred to as the latent space.
 Click the image to learn
Click the image to learn
more about Deep Learning
Design Patterns from
Manning Publications.
Take 35% off any format
by entering ttferlitsch into
the discount code box
at checkout.
The task component uses the representation of the input in the latent space to learn the task of the model. In our example, the task is to classify the image, for instance as a cat or dog.
While my book focuses on convolutional neural networks, this macro-architecture of stem, learner and task components can be applied to other neural network architectures, such as transformer networks with attention mechanisms used in natural language processing.
Now let's look at the basic architecture in code with a skeleton template using the TensorFlow Keras functional API. In the following code sample, you get a high-level view of the data flow between the three components. The skeleton consists of two main parts: the function, or procedural input/output definitions of the major components (stem, learner and task); and the input, which is a tensor that flows into the stem and the assembling of the components.
def stem(input_shape): #A
''' stem layers
Input_shape : the shape of the input tensor
'''
return outputs
def learner(inputs): #B
''' leaner layers
inputs : the input tensors (feature maps)
'''
return outputs
def task(inputs, n_classes): #C
''' classifier layers
inputs : the input tensors (feature maps)
n_classes : the number of output classes
'''
return outputs
inputs = Input(input_shape=(224, 224, 3)) #D
x = stem(inputs)
x = learner(x)
outputs = task(x, n_classes=1000)
model = Model(inputs, outputs) #E
#A constructs the stem component.
#B constructs the learner component.
#C constructs the task component.
#D defines the input tensor.
#E assembles the model.
TensorFlow Keras
If you are not familiar with TensorFlow Keras constructs such as the class Input and Model, I recommend reading up on them. My Deep Learning Primer, which covers the more basic steps and components of deep learning, is one resource to consult; it is available for free online.
In this code example, the class Input defines the input tensor to the model. In the case of a CNN, that tensor consists of the shape of the image. The tuple (224, 224, 3) refers to a 224x224 RGB (3-channel) image. The class Model is the final step when coding the neural network using the TensorFlow.Keras functional API. This is the final build step, and is referred to as the compile() method. The parameters to the Model class are the model input tensor(s) and output tensor(s). In our example, we have a single input and single output tensor.
The stem component
The stem component is the entry point to the neural network. Its primary purpose is to perform the first, coarse-level feature extraction while reducing the feature maps to a size designed for the learner component. More specifically, the number of feature maps and the feature map sizes outputted by the stem component are designed by balancing two critical criteria. We need to:
- Maximize the feature extraction for coarse-level features, such that the model has enough information to learn finer level features within the model's capacity; and
- Minimize the number of parameters in the downstream learner component, such that the size and time to train the model is minimized without affecting the model's performance.
This initial task is performed by the stem convolutional group. A number of well-known CNN models use different approaches in the stem group to perform this balancing act. Here, let's look at an early version, VGG, which is considered the parent of modern CNNs.
VGG design pattern
The VGG architecture won the 2014 ImageNet Large Scale Visual Recognition Competition for image classification. The VGG formalized the concept of constructing a CNN into components and groups using a pattern. Prior to VGG, CNNs were constructed as ConvNets, whose usefulness did not go beyond academic novelties. That is, VGGs were the first to have practical applications in production. For several years, researchers continued to compare more modern architecture developments to the VGG in their ablation studies and to use VGGs for the classification backbone of early object-detection models.
Along with Inception, VGG formalized the concept of having a first convolutional group that did a coarse-level feature extraction; we now refer to this group as the stem component. Subsequent convolutional groups then performed finer levels of feature extraction. These groups also did feature learning, which we now call representational learning. Hence the term "learner" for this component.
The stem component for a VGG, as depicted in the following figure, was designed to take a 224x224x3 image as input and then output 64 feature maps, each at 224x224. The VGG stem group did no size reduction of the feature maps. The convention of outputting 64 coarse-level feature maps continues today, and the stem of modern CNNs typically output 32 or 64 feature maps.
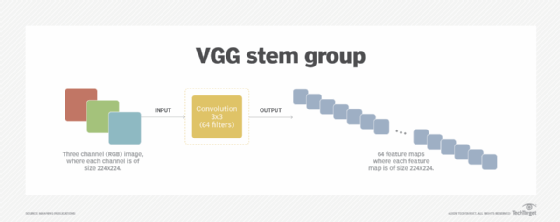
Below is a sample for coding the VGG stem component in the idiomatic design pattern, which consists of a single convolutional layer. In TensorFlow Keras, it is the layer Conv2D. This layer uses a 3x3 filter for coarse-level feature extraction for 64 filters. It does not reduce the size of the feature maps. With a (224, 224, 3) image input (standard for images from the ImageNet dataset), the output from this stem group will be (224, 224, 64).
def stem(inputs):
""" Construct the Stem Convolutional Group
inputs : the input tensor
"""
outputs = Conv2D(64, (3, 3), strides=(1, 1), padding="same",
activation="relu")(inputs)
return outputs
Github provides a complete code rendition using the idiomatic procedure reuse design pattern for VGG.
Eventually, researchers discovered the drawback of a VGG stem. By retaining the size of the input (224x224) in the extracted coarse feature maps, it resulted in an unnecessary number of parameters entering the learner. This, in turn, increased the memory footprint and reduced performance for training and prediction. Subsequent state-of-the-art models added pooling in the stem component, decreasing memory footprint and increasing performance without a loss in accuracy.







