Sergey - stock.adobe.com
2 data-wrangling techniques for better machine learning
Before data can be usefully inputted into algorithms, it must first be prepared. Learn two of the techniques that do the job and make machine learning work.
This article is excerpted from the course "Fundamental Machine Learning," part of the Machine Learning Specialist certification program from Arcitura Education. It is the seventh part of the 13-part series, "Using machine learning algorithms, practices and patterns."
This article explains machine learning data-wrangling techniques that help to make data ready as input for a chosen machine learning algorithm. These techniques enable conversion of values from categorical to numerical, and vice versa, filling in missing data and bringing data values in a known range via normalization. This article covers the following two of four data-wrangling techniques: feature imputation and feature encoding. As explained in Part 4, these techniques are documented in a standard pattern profile format.
Feature imputation: Overview
- How can a data set with missing feature values be used for model development without having to delete entire rows or columns of valuable data?
- One way to utilize a data set containing missing values is to delete entire rows or columns of data. However, this comes at the expense of losing valuable data that could have contributed toward developing a more accurate model.
- Instead of deleting data, the value of missing features is inferred from the rest of the features through the application of statistical techniques or machine learning algorithms.
- Statistical techniques, such as mean, median or mode, or machine learning algorithms, such as k-nearest neighbors (KNN) and linear regression, are applied to the data set to find the values of the missing fields.
Feature imputation: Explained
Problem
It is rare that acquired data contains values for all features of all instances. Values can go missing for a number of reasons -- for example, through a faulty sensor, software bug, mapping issues from the source system or being left intentionally blank in a survey.
To be able to use such a data set for model training, since machine learning algorithms require a value to work with, a quick and easy solution is to delete either the entire instances (rows) with missing values or delete the feature (column). However, doing so negatively impacts model training as deleting instances not only decreases the amount of training data, but also creates an imbalance in the example training data. In addition, removing features altogether affects the predictive power of the resulting model (Figure 1).
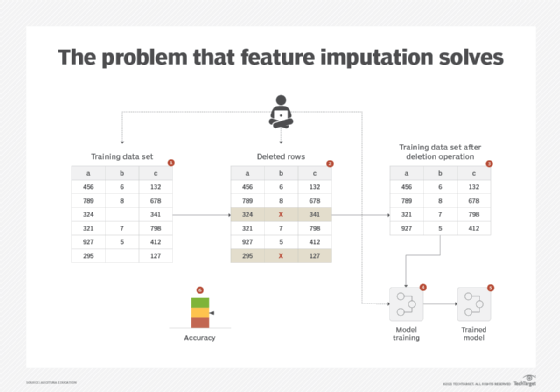
Solution
The features or instances are not deleted, and the values of the missing fields are calculated from other fields. Either the nonmissing values of the respective feature are used, or the value can be extrapolated from other feature(s).
Application
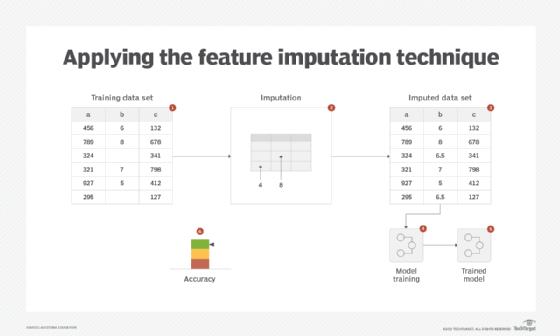
Mean, median, or mode can be used to compute the missing values. As the average value is used for imputation, the resulting data set may have a reduced variance compared to the one without missing values.
Another technique for numerical data is the use of linear regression. From the data set, via correlation, the best correlated feature -- without missing values -- to the feature with missing values is found. Then, using the linear regression equation, the known value of the feature without a missing value is input to find the missing value of the other feature. Although this technique does not suffer from the variance reduction problem, it does assume a linear relationship between features, which may not always be accurate.
For categorical features, either mode or a constant value, such as N/A, can be used that becomes another category for that feature. In cases where the missing values feature is the target, this constant value can be treated as a separate class (Figure 2).
Feature encoding: Overview
- How can categorical features be used for model development when the underlying machine learning algorithm only supports numerical features?
- Most machine learning algorithms can only accept numerical features as input, which makes the inclusion of valuable categorical features impossible as an input for model development.
- All categorical features in the data set are converted to a numeric representation using a mathematical function.
- The categorical features are encoded to numerical features using a specific encoding scheme, such as label encoder and one hot encoder.
Feature encoding: Explained
Problem
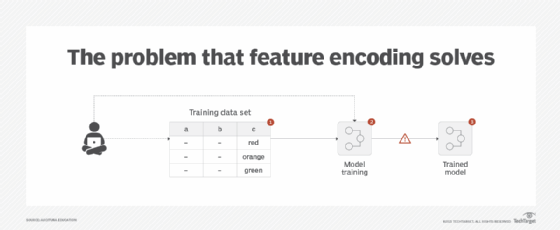
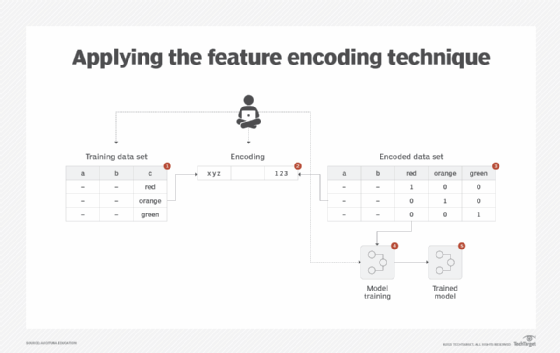
A training data set normally contains both numerical and categorical data. However, most machine learning algorithms are unable to work with categorical features. This is because such algorithms need to perform mathematical operations -- for example, addition and multiplication -- and carry out comparisons on feature values. On a higher level, algorithms such as KNN and K-means perform distance measurement, which is not possible with categorical values. Excluding categorical features for model training can severely impact the efficacy of the model. In other cases, exclusion might not be an option at all if the target class itself comprises categorical values, such as cat, dog or wolf (Figure 3).
Solution
Categorical features are converted to numerical features via reversible mathematical operations that make it possible to retrieve the original categorical value from the converted numerical value. The conversion is performed in such a way that the resulting numerical value does not make one feature more important than the other. The process normally involves first mapping each unique value to a number.
Although the new value of the categorical feature is a now numerical value, using it as is for model training can misrepresent the facts. For example, consider a fruit feature containing values such as orange, apple and banana. After step one, the corresponding values are 0, 1 and 2, respectively. This means that instances with banana values for the fruit feature may get more weight than the ones with orange values. To rectify this issue, another step is required where the numerical values from the previous step become new features (columns), and for instances (rows) where a certain numerical value appears, the corresponding feature (column) contains a value of 1, while other columns contain a value of 0.
Continuing with the previous example, consider an instance where the fruit value is 2. After step two, the same instance will have three additional features (columns): 0, 1 and 2, where features 0 and 1 have values of 0, while feature 2 has a value of 1.
Application
A label encoder is first applied to the categorical features followed by the application of a one hot encoder. Both of these encoders are generally applied using data pre-processing functions available either within the model development software or as a separate library that can be imported (Figure 4).
What's next?
The next article covers the feature discretization and feature standardization data-wrangling patterns.
View the full series
This lesson is one in a 13-part series on using machine learning algorithms, practices and patterns. Click the titles below to read the other available lessons.
Lesson 1: Introduction to using machine learning
Lesson 2: The supervised approach to machine learning
Lesson 3: Unsupervised machine learning: Dealing with unknown data
Lesson 4: Common ML patterns: Central tendency and variability
Lesson 5: Associativity, graphical summary computations aid ML insights
Lesson 6: How feature selection, extraction improve ML predictions
Lesson 7
Lesson 8: Wrangling data with feature discretization, standardization
Lesson 9: 2 supervised learning techniques that aid value predictions
Lesson 10: Discover 2 unsupervised techniques that help categorize data
Lesson 11: ML model optimization with ensemble learning, retraining
Lesson 12: 3 ways to evaluate and improve machine learning models
Lesson 13: Model optimization methods to cut latency, adapt to new data