Databricks' new products take aim at simplifying machine learning integration -- something that has become increasingly difficult, as the number of tools has multiplied.
SAN FRANCISCO -- Open source machine learning frameworks have multiplied in recent years, as enterprises pursue operational gains through AI. Along the way, the situation has formed a jumble of competing tools, creating a nightmare for development teams tasked with supporting them all.
Databricks, which offers managed versions of the Spark compute engine in the cloud, is making a play for enterprises that are struggling to keep pace with this environment. At Spark + AI Summit 2018, which was hosted by Databricks here this week, the company announced updates to its platform and to Spark that it said will help bring the diverse array of machine learning frameworks under one roof.
Unifying machine learning frameworks
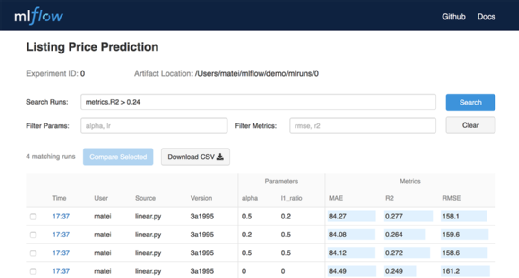
MLflow is a new open source technology available on the Databricks platform that integrates with Spark, SciKit-Learn, TensorFlow and other open source machine learning tools. It allows data scientists to package machine learning code into reproducible modules, conduct and compare parallel experiments, and deploy models that are production-ready.
MLflow adds machine learning workflow management capabilities to the Databricks Unified Analytics Platform, the San Francisco company's hosted environment for teams of data scientists and data engineers. The Spark-based offering competes with collaborative data science workbench platforms from several other vendors, including Cloudera, Domino Data Lab, IBM and DataScience.com, which Oracle bought last month.
Databricks also introduced a new product called Runtime for ML. This is a preconfigured Spark cluster that comes loaded with distributed machine learning frameworks commonly used for deep learning, including Keras, Horovod and TensorFlow, eliminating the integration work data scientists typically have to do when adopting a new tool.
Databricks' other announcement, a tool called Delta, is aimed at improving data quality for machine learning modeling. Delta sits on top of data lakes, which typically contain large amounts of unstructured data. Data scientists can specify a schema they want their training data to match, and Delta will pull in all the data in the data lake that fits the specified schema, leaving out data that doesn't fit.
MLflow includes a tracking interface for logging the results of machine learning jobs.
Users want everything under one roof
Each of the new tools is either in a public preview or alpha test stage, so few users have had a chance to get their hands on them. But attendees at the conference were broadly happy about the approach of stitching together disparate frameworks more tightly.
Saman Michael Far, senior vice president of technology at the Financial Industry Regulatory Authority (FINRA) in Washington, D.C., said in a keynote presentation that he brought in the Databricks platform largely because it already supports several query languages, including R, Python and SQL. Integrating these tools more closely with machine learning frameworks will help FINRA use more machine learning in its goal of spotting potentially illegal financial trades.
You have to take a unified approach. Pick technologies that help you unify your data and operations.
John Golesenior director of business analysis and product management at Capital One
"It's removed a lot of the obstacles that seemed inherent to doing machine learning in a business environment," Far said.
John Gole, senior director of business analysis and product management at Capital One, based in McLean, Va., said the financial services company has implemented Spark throughout its operational departments, including marketing, accounts management and business reporting. The platform is being used for tasks that range from extract, transform and load jobs to SQL querying for ad hoc analysis and machine learning. It's this unified nature of Spark that made it attractive, Gole said.
Going forward, he said he expects this kind of unified platform to become even more valuable as enterprises bring more machine learning to the center of their operations.
"You have to take a unified approach," Gole said. "Pick technologies that help you unify your data and operations."
Bringing together a range of tools
Engineers at ride-sharing platform Uber have already built integrations similar to what Databricks unveiled at the conference. In a presentation, Atul Gupte, a product manager at Uber, based in San Francisco, described a data science workbench his team created that brings together a range of tools -- including Jupyter, R and Python -- into a web-based environment that's powered by Spark on the back end. The platform is used for all the company's machine learning jobs, like training models to cluster rider pickups in Uber Pool or forecast rider demand so the app can encourage more drivers to get out on the roads.
Gupte said, as the company grew from a startup to a large enterprise, the old way of doing things, where everyone worked in their own silo using their own tool of choice, didn't scale, which is why it was important to take this more standardized approach to data analysis and machine learning.
"The power is that everyone is now working together," Gupte said. "You don't have to keep switching tools. It's a pretty foundational change in the way teams are working."