
kirill_makarov - stock.adobe.com
14 best machine learning platforms for 2020
Turn ever-growing volumes of data into enterprise insights with the right platform for machine learning. Learn more about the vendors and products in this cutting-edge market.

Organizations want a competitive edge and look to platforms for machine learning that provide a means to predict outcomes from ever-growing volumes of data. This roundup of machine learning platforms is not exhaustive but highlights market-leading vendors and products.
1. Alteryx Promote
The Alteryx Promote API enables data scientists to deploy predictive models into business systems and then manage model performance.
Alteryx claims its platform for machine learning helps data professionals solve complex business problems faster by making it easier to deploy advanced analytics models into production.
Alteryx Promote extends the analytics capabilities of Alteryx Analytics Platform as an end-to-end system for data science teams to deploy and update predictive models free from IT. When dealing with production apps capable of using REST API requests, the platform embeds predictive and machine learning models without recoding. It also administers the models both on premises and in a cloud, with scalable options.
By developing models in the "Alteryx code-friendly environment" and deploying to a secure cloud, companies can expect to cut model deployment time to minutes, the company states. The process produces the resulting API as a single line of code that teams can easily incorporate into HTML websites.
2. Amazon SageMaker
SageMaker is a key component of Amazon's machine learning offering, through its AWS public cloud.
It's a fully managed service, built for software developers and data scientists to create, train and deploy machine learning models. The cloud-based service includes modules that organizations can use together or separately.
Hosted Jupyter notebooks are a component, and these notebooks enable users to explore and visualize training data stored in Amazon Simple Storage Service (S3), an AWS service that provides object storage through web services interfaces. The notebooks can connect directly to data in Amazon S3 or use AWS Glue to move data from Amazon Relational Database Service, Amazon DynamoDB and Amazon Redshift into S3 for analysis.
Amazon touts SageMaker as a means to easily and quickly create, deploy and train models, and to that end, SageMaker includes 12 common machine learning algorithms that are preinstalled. The service also comes preconfigured to run TensorFlow and Apache MXNet. Customers can also use their own frameworks.
3. Domino
The Domino platform for machine learning is open and unified, designed to accelerate research and collaboration, increase iteration speed and remove deployment friction. Domino claims it offers a fully functional platform by enabling users to build, validate and deliver models at scale.
Enterprises can use the platform to discover, share and reuse data sources, including cloud databases and distributed systems, such as Hadoop and Spark. They can also run development and production workloads in configurable Docker containers to create shared and reusable environments and utilize Kubernetes-backed scalable computing in both vertical and horizontal scale resources. The latter is available in either cloud or on premises. The platform can use deep learning techniques with access to GPU hardware as well.
The Domino platform enables users to spin up interactive workspaces using any web-based tool, such as Jupyter, RStudio, SAS, H2O and Zeppelin. It runs many training and tuning jobs simultaneously, while also tracking key model metrics and comparing results side by side.
It can also automatically preserve an experiment's context. Each time a user runs an experiment, this platform for machine learning captures the full set of model dependencies -- data, code, packages/tools, parameters and results -- and the discussion of the experiment's results, Domino states. The system delivers models as enterprise-grade batch or real-time APIs for integration into downstream systems.
In early 2020, Domino released their Domino Model Monitor, which tracks model drift and inaccuracies in real time to prevent model degradation.
4. Google Cloud Machine Learning Engine
Google offers Cloud Machine Learning Engine (ML Engine) as a managed service that enables data scientists development and real-time enablement . It provides training and prediction services, which data scientists can use together or individually.
Cloud Machine Learning Engine combines the managed infrastructure of Google Cloud Platform (GCP) with TensorFlow, an open source software library for dataflow programming across a variety of tasks. Enterprises can use the service to train machine learning models at scale by running TensorFlow training applications in the cloud. They can also host the trained models in the cloud and then use them to make predictions about new data.
The Google service manages the computing resources a company needs to run a training job, so it can focus more on its model than on hardware configurations or resource management.
Cloud ML Engine has several key components -- one of them being a REST API, the Engine core that is a set of RESTful services to manage jobs, models and versions, as well as make predictions on hosted models on GCP. Another component is the gcloud command-line tool, which manages models, as well as version and request predictions. Another element, Google Cloud Console, provides model and version management and a graphical interface for working with machine learning resources.
5. H2O.ai
H2O is an open source, in-memory, distributed platform for machine learning that enables organizations to build machine learning models on large data.
H2O Flow utilizes interactive notebooks, has linear scalability and supports common statistical and machine learning algorithms, including gradient boosting machine (GBM), generalized linear model (GLM) and deep learning, including deep neural networks.
H2O has an AutoML functionality that automatically runs through algorithms and their hyperparameters to produce a leaderboard of the best models.
Other key features include procedures developed for distributed computing. The algorithms are for both supervised and unsupervised approaches, including random forest, GLM, GBM, XGBoost, generalized low rank model, Word2vec and more.
H2O works on existing big data infrastructure, either on bare metal or on top of existing Hadoop or Spark clusters. The software can ingest data directly from Hadoop Distributed File System, Spark, S3, Azure Data Lake or another information source. Use cases include advanced analytics, fraud detection, claims management and digital advertising.

6. IBM Watson Studio and IBM Watson Machine Learning
IBM Watson Studio and IBM Watson Machine Learning compose an enterprise data science platform for machine learning, which provides teams with open source and data science tools. IBM touts them as offering the flexibility to build and deploy anywhere in a multi-cloud environment and the ability to operationalize data engineering results faster.
Watson Studio enables data scientists and engineers to explore data and develop models. The platform enables users to access data science tools for data preparation and model development and is available for both coders and noncoders. By using a multi-cloud environment, IBM Watson Studio provides data analytics on premises, in IBM Cloud Private or in the public cloud.
With IBM Watson Machine Learning, models built in IBM Watson Studio are production-ready, built for deployment, evaluation and management in a secure environment. This enables users to put data science into production faster, IBM states.
7. IBM Machine Learning for z/OS
IBM Machine Learning for z/OS is a machine learning system designed to extract hidden value from enterprise data. It can help organizations quickly ingest and transform data to create, organize and manage self-learning behavioral models using IBM Z systems data. IBM claims that this, in turn, enables companies to more accurately anticipate customer and business needs.
Data developers and scientists can build and train models with IBM Watson Studio or other model development environments and have the ability to deploy those models close to core transactions that originate on IBM Z.
Users can deploy the models instantaneously within IBM's framework, and RESTful APIs enable application developers to incorporate behavioral models into their code. The dashboard provides a health check across all models in the enterprise, offering insight into overall model performance and a quick view of those that need to be retrained.
Model accuracy enables data scientists and engineers to schedule continuous reevaluations on new data.
8. IBM SPSS Modeler
IBM SPSS Modeler provides data mining and text analysis for users with little to no programming skills. SPSS Modeler can read data from flat files, spreadsheets, major relational databases, IBM Planning Analytics and Hadoop.
According to IBM, users can extend the capabilities of SPSS Modeler to push back data processing with the SQL Optimization add-on (subscription) or Analytic Server (perpetual license). The product provides a graphical interface to help visualize each step in the data mining process as part of a stream and automatically transforms data into the best format for accurate predictive modeling.
In addition, SPSS Modeler can test numerous modeling methods, compare results and select which model to deploy in a single run. This process informs users of the best-performing algorithm based on model performance. Additionally, SPSS Modeler offers multiple machine learning techniques and supports decision trees, neural networks and regression models.
9. IBM Watson Explorer
IBM Watson Explorer is a cognitive exploration and content analysis platform that enables users to explore and analyze structured, unstructured, internal, external and public content to uncover trends and patterns. For example, organizations have used Watson Explorer to understand incoming calls and emails through Watson's built-in cognitive capabilities, machine learning models, natural language processing (NLP) and APIs. Ultimately, Watson enables organizations to gain a better view of customers.
IBM Watson Explorer uses machine learning, cognitive data mining and rich text analytics. The technology also utilizes indexing and searching; this enables users to explore, aggregate, analyze and visualize large volumes of structured and unstructured data.
10. Knime Analytics Platform
Knime Analytics Platform is open source software for creating data science applications and services, with an aim to be intuitive and open, while continuously integrating new developments. According to its developers, Knime's ultimate goal is to make understanding data and designing data science workflows and reusable components accessible to everyone.
Data professionals can use the platform to create visual workflows with a drag-and-drop graphical interface, without the need for coding.
Users can choose from more than 2,000 modules or nodes to build workflows, model each step of an analysis, control the flow of data and ensure that work is always current. They can select one of the hundreds of publicly available example workflows or use an integrated workflow coach to guide them.
Using the Knime platform for machine learning, data analysts can derive statistics -- including mean, quantiles and standard deviation -- or apply statistical tests to validate a hypothesis. They can build machine learning models for classification, regression, dimension reduction or clustering using advanced algorithms. This also includes deep learning, tree-based methods and logistic regression.
11. Microsoft Azure Machine Learning Studio
Microsoft Azure Machine Learning Studio is a collaborative, drag-and-drop tool that data teams can use to build, test and deploy predictive analytics on data. Machine Learning Studio publishes models as web services applications or business intelligence tools, such as Excel, Microsoft touts.
The product provides an interactive, visual workspace, where users can drag and drop data sets and analysis modules onto an interactive canvas, connecting them together to form an experiment. This then runs in Machine Learning Studio.
As users build experiments, they can choose from a list of modules with potential parameters to configure the module's internal algorithms. When a user selects a module on the canvas, the tool displays the module's parameters in a properties pane, and the user can modify the limitations in that pane to tune the model.
To iterate on the model design, a user can edit the experiment, save a copy if needed and run it again. They can then publish the training experiment as a web service so that others can access the model and later convert it to a predictive trial. There is no programming required, Microsoft states, just a need to visually connect data sets and modules to construct the predictive analysis model.
Bonus: Microsoft Azure Computer Vision offers data scientists the ability to run image processing and classifying algorithms for image detection, classification, etc.
12. Microsoft SQL Server Machine Learning Services
According to Microsoft, SQL Server Machine Learning Services is an embedded, predictive analytics and data science engine. It can execute R and Python code within an SQL Server database as either stored procedures, Transact-SQL script containing R or Python statements, or R or Python code containing T-SQL.
One of the key value propositions of Machine Learning Services is the ability of its proprietary packages to deliver advanced analytics at scale and the ability to bring calculations and processing to where the data resides. Doing so eliminates the need to pull data across the network, the company says.
There are two options for using machine learning capabilities in SQL Server. One is SQL Server Machine Learning Services (In-Database), which operates within the database engine instance and fully integrates the calculation engine with the database engine.
The other is SQL Server Machine Learning Server (Standalone), a Machine Learning Server for Windows that runs independently of the database engine. Although it uses the SQL Server setup to install the server, the feature is not instance-aware. Functionally, it is equivalent to the non-SQL Server Microsoft Machine Learning Server for Windows.
Support for R and Python is through proprietary Microsoft packages used for creating and training models, scoring data and parallel processing using the underlying system resources.
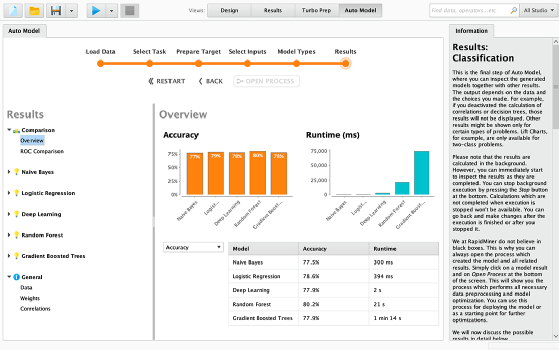
13. RapidMiner
RapidMiner is a software platform for machine learning, built for analytics teams, and it unites data preparation, machine learning and predictive model deployment. Organizations can build machine learning models and put them into production using RapidMiner's visual workflow designer and automated modeling capabilities.
RapidMiner supports a variety of use cases, including customer intelligence, supply chain optimization, healthcare outcomes improvement, predictive maintenance, cybersecurity and fraud detection.
RapidMiner Auto Model speeds data preparation by analyzing data to identify common data quality problems. It automates predictive modeling by suggesting the best machine learning techniques and then generates optimized, cross-validated predictive models. RapidMiner then highlights which features have the greatest impact on the desired business objective.
Built-in visualizations and an interactive model simulator enable data scientists to quickly explore a prototype to judge performance under a variety of conditions.
RapidMiner converted its previous server into the RapidMiner AI hub, an open-source collaboration server to boost computation, connect data science teams, and help automate decision processes.
14. SAS Visual Data Mining and Machine Learning
Visual Data Mining and Machine Learning from SAS supports end-to-end data mining and machine learning processes. With a visual and programming interface that handles all analytical lifecycle key tasks, this platform for machine learning lets multiple users concurrently analyze any amount of structured and unstructured data with a visual interface.
The product offers scalable, in-memory analytical processing, enabling concurrent access to data in a secure, multiuser environment, according to SAS. Data and analytical workload operations are distributed across nodes, in parallel, and are multithreaded on each node for fast speed.
A drag-and-drop interface lets data engineers quickly augment and integrate data within a "visual pipeline of activities." All actions are performed in memory to maintain data structure consistency. The system lets users explore all textual data to gain new insights about unknown themes and connections and provides access to a broad set of statistical, machine learning, deep learning and text analytics algorithms in a single environment.
Analytical capabilities include clustering, different flavors of regression, random forests, GBM, support vector machines, NLP and topic detection. Analysts can test different model training approaches in a single run and compare results of multiple supervised learning algorithms with standardized tests to identify top models.
Visual Data Mining and Machine Learning also enables users to embed open source code within an analysis and call open source algorithms seamlessly within a Model Studio flow. This facilitates collaboration across an organization, the company says, because users can program in the programming language of their choice.
Editor's note
Using extensive research of the machine learning platform market, TechTarget editors focused on established and market-leading vendors, as well as those offering unique functionality. Our research included data from TechTarget surveys, as well as reports from other respected research firms, including Gartner.





