
ktsdesign - stock.adobe.com
Understanding how deep learning black box training creates bias
Bias in AI is a systematic issue that derails many projects. Dismantling the black box of deep learning algorithms is crucial to the advancement and deployment of the technology.

It's not uncommon to see the term black box used in reference to AI, particularly when it comes to machine learning. And it's important to have clarity about just why that term is being used because, when it's used accurately, it can portend real trouble.
The term black box on its face means a device with obscure inner workings. To be fair, AI does seem mysterious to most people -- even in IT -- who don't work with it a great deal; a vast amount of data goes in one end, and uncanny insights and predictions come out the other. But it's not all that mysterious -- most of the time. However, the introduction of deep learning and neural networks has complicated the ability for data scientists to peek into the inner workings of a model and work with its outputs. This is what's leading to deep learning black box bias issues, where data enters the model and exports an output that can't be reverse-engineered or explained.
What 'machine learning' means
All machine learning is AI, but not all AI is machine learning. When we talk about the AI mentioned above -- big data, insight generation and predictive systems -- more often than not, we're talking about machine learning.
It's important to get this defined correctly for reasons that will become apparent. A machine learning system is an automated process that ingests data continuously -- or, at least, regularly – and that passes through a problem-solving model, which generates outcomes. The problem being solved is well understood, and the algorithm solving it began in a human mind. What sets machine learning apart is that such systems improve over time, without human assistance; as outcomes improve, the algorithm doing the work self-tunes.
There's nothing mysterious about it, and once it's understood that the only part of the process that isn't under human scrutiny is the minor details of the tuning, it all clicks.
But there's another layer to machine learning that's altogether mysterious. It's called deep learning, and it's the black box that can lead to serious concerns. In deep learning, as with machine learning, the system improves over time by examining outcomes, but unlike machine learning, deep learning does not rely on conventional data-parsing algorithms. It utilizes a mechanism called a neural network, a distributed system of weighted nodes that mimic human neurons and mold a statistical solution space over time. It changes over time, but the changes are obscure.
Put another way, even when a deep learning system is operating at peak performance, it truly is a black box -- what's going on inside is anybody's guess.
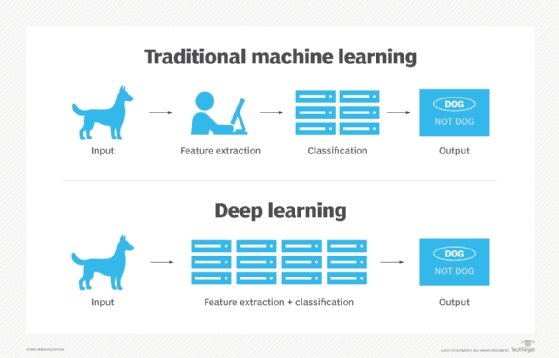
The dangers of a black box
The troubling issue is readily apparent. Increasingly, AI is being used in the enterprise for decision support at every level, from the folks who order spare parts to the C-suite. It's there that real concerns can arise: If a top-tier executive is making a mission-critical decision and the decision is based on insight from an AI system that is inscrutable, how can the executive explain in hindsight why the decision was made? No one can say with any certainty what's going on in deep learning black box training.
This can lead to problems with accountability, compliance and audit trails when decisions do go awry for reasons that aren't clear. It's impossible to explain a decision when the person responsible was just trusting the machine and can't reverse-engineer the decision itself. For all practical purposes, what's going on in the black box is analogous to what would be called intuition in a human being -- and that explanation is impractical when things go wrong and compliance officers are demanding answers.
Those who sit highest in the decision-making hierarchy of the enterprise often look at AI with a skeptical eye: Why should they trust this machine? It doesn't have their experience, savvy or know-how; if no one, not even the company's brainiest data scientist, can explain how it's coming up with its answers, then they're naturally suspect. Similarly, media coverage of bias, compliance and black box systems causing problems heightens anxiety around these systems.
In 2018, Amazon created an AI-based recruiting software that it hoped would identify the best candidates from a decade of employment applications and interviews, with the resulting hires as outcomes. The system was thoroughly trained on that data, and the resulting model was used to score new candidates. The problem was: The system favored male candidates over female candidates for no obvious coding reason. In the long run, developers learned that the model was flawed because the training data was tainted. The old employment applications and interviews had captured the gender bias of the interviewers, and the AI had dutifully learned gender bias from its teachers. But there was no way to understand that from examining the black box itself -- and a long road to fixing it.
Peering into the dark
The challenge becomes: How can the inner workings of deep learning black boxes be at least modestly illuminated to get past the trust issue? When it's important to understand why a decision was made, can data scientists get specifics about a decision?
Here are some possibilities for dismantling the black box and making AI more explainable.
Have an AI watch the AI. The barrier to transparency in a black box AI system is not observing its learning process. However, another AI could do that and simultaneously provide insight into its workings. This technique is called Layer-wise Relevance Propagation, which scores the various features of an input vector according to how strongly they contributed to the output. This shines a light on what was important or not in the AI's training.
Local interpretability. There's a vast difference between how a black box AI works in general and why it gave the output it did in a particular case. Gaining insight into how a particular output was produced by running additional samples similar to the one in question, varying inputs and studying the output on results can be helpful in diagnosing a decision when it must be reverse-engineered for audit or regulatory reasons.
Prescreen for data bias. As mentioned above, biased data results in a biased AI. Unfortunately, bias may not be obvious until trouble occurs since the AI is not transparent. Data scientists must scan for data bias with human eyes ahead of inputting it in the model -- and cleaning the data accordingly.
A responsible future
The black box problem is serious enough that regulatory bodies are beginning to emerge. In 2018, the Association for Computing Machinery Conference on Fairness, Accountability and Transparency -- a peer-reviewed academic conference series about AI ethics -- was established to study the problem and produce solutions to the issues of AI transparency and explainability. The EU's GDPR now includes a right to explanation to deal with algorithmic opacity. And, in the U.S., insurance companies are not permitted to employ AI processes that obscure the explanations of rate and coverage decisions. Major cities -- like Boston -- are voting to ban the use of facial recognition technology by city officials.
Deep learning is tremendously powerful and useful. But the black box problem isn't an easy one, and it's not going away anytime soon. The best rule of thumb: Use with caution.







