A guide to artificial intelligence in the enterprise
AI in the enterprise is changing how work is done, but companies must overcome various challenges to derive value from this powerful and rapidly evolving technology.

The application of artificial intelligence in the enterprise is profoundly changing the way businesses work. Companies are incorporating AI technologies into their business operations with the aim of saving money, boosting efficiency, generating insights and creating new markets.
There are AI-powered enterprise applications to enhance customer service, maximize sales, sharpen cybersecurity, optimize supply chains, free up workers from mundane tasks, improve existing products and point the way to new products. It is hard to think of an area in the enterprise where AI -- the simulation of human processes by machines, especially computer systems -- won't have an impact. However, enterprise leaders determined to use AI to improve their businesses and ensure a return on their investment face big challenges on several fronts:
- The domain of artificial intelligence is changing rapidly because of the tremendous amount of AI research being done. The world's biggest companies, research institutions and governments around the globe are supporting major research initiatives on AI.
- There are a multitude of AI use cases: AI can be applied to any problem facing a company or to humankind writ large.
- To reap the value of AI in the enterprise, business leaders must understand how AI works, where AI technologies can be aptly used in their businesses and where they cannot. This is a daunting proposition because of AI's rapid evolution and numerous use cases.
This wide-ranging guide to artificial intelligence in the enterprise provides the building blocks for becoming successful business consumers of AI technologies. It starts with introductory explanations of AI's history, how AI works and the main types of AI. The importance and impact of AI is covered next, followed by information on the following critical areas of interest to enterprise AI users:
- AI's key benefits and risks.
- Current and potential AI use cases.
- Building a successful AI strategy.
- Steps for implementing AI tools in the enterprise.
- Technological breakthroughs that are driving the field forward.
Throughout the guide, we include hyperlinks to TechTarget articles that provide more detail and insights on the topics discussed.
What are the origins of artificial intelligence?
The modern field of AI is often dated to 1956, when the term artificial intelligence was coined in the proposal for an academic conference held at Dartmouth College that year. But the idea that the human brain can be mechanized is deeply rooted throughout human history.
Myths and legends, for example, are replete with statues that come to life. Many ancient cultures built humanlike automata that were believed to possess reason and emotion. By the first millennium B.C., philosophers in various parts of the world were developing methods for formal reasoning -- an effort built upon over the next 2,000-plus years by contributors that also included theologians, mathematicians, engineers, economists, psychologists, computational scientists and neurobiologists.
Below are some milestones in the long and elusive quest to recreate the human brain:
- Rise of the modern computer. The prototype for the modern computer is traced to 1836 when Charles Babbage and Augusta Ada Byron, Countess of Lovelace, invented the first design for a programmable machine. A century later, in the 1940s, Princeton mathematician John von Neumann conceived the architecture for the stored-program computer: This was the idea that a computer's program and the data it processes can be kept in the computer's memory.
- Birth of the neural network. The first mathematical model of a neural network, arguably the basis for today's biggest advances in AI, was published in 1943 by the computational neuroscientists Warren McCulloch and Walter Pitts in their landmark paper, "A Logical Calculus of Ideas Immanent in Nervous Activity."
- Turing Test. In his 1950 paper, "Computing Machinery and Intelligence," British mathematician Alan Turing explored whether machines can exhibit humanlike intelligence. The Turing Test, named after an experiment proposed in the paper, focused on a computer's ability to fool interrogators into believing its responses to their questions were made by a human being.
- Historic meeting in New Hampshire. A 1956 summer conference at Dartmouth College, sponsored by the Defense Advanced Research Projects Agency, or DARPA, was a gathering of luminaries in this new field. The group included Marvin Minsky, Oliver Selfridge and John McCarthy, who is credited with coining the term artificial intelligence. Also in attendance were AI notables Allen Newell and Herbert A. Simon, who presented their groundbreaking Logic Theorist -- a computer program capable of proving certain mathematical theorems and referred to as the first AI program.
- Fruitful days for AI research. The promise of developing a thinking machine on par with human understanding led to nearly 20 years of well-funded basic research that generated significant advances in AI. Examples include Lisp, a language for AI programming that is still used today; Eliza, an early natural language processing (NLP) program that laid the foundation for today's chatbots; and the groundbreaking work by Edward Feigenbaum and colleagues on DENDRAL, the first expert system.
- AI famine. When the development of an AI system on par with human intelligence proved elusive, funders pulled back, resulting in a fallow period for AI research from 1974 to 1980 that is known as the first AI winter. In the 1980s, industry adoption of Knowledge-based systems, including expert systems, ushered in a new wave of AI enthusiasm only to be followed by another collapse of funding and support. The second AI winter lasted until the mid-1990s.
- Big data and deep learning techniques spark AI revival. Groundbreaking work in 1989 by Yann LeCun, Yoshua Bengio and Patric Haffner showed that convolutional neural networks (CNNs) could be applied to real-world problems, propelling an AI renaissance that continues to this day. Notable breakthroughs include the 2012 debut of deep CNN architectures based on work by Geoffrey Hinton and colleagues, which triggered an explosion of research on deep learning, a subset of AI and machine learning.
- AI captures public imagination. IBM's Deep Blue captivated the public in 1997 when it defeated chess master Garry Kasparov, marking the first time a computer triumphed over a reigning chess champion in a tournament setting. In 2011, an IBM AI system again took popular culture by storm when supercomputer Watson competed on Jeopardy! and outscored the TV game show's two most successful champions. In 2016, DeepMind's AlphaGo defeated the world's top Go player, drawing comparisons to Deep Blue's victory nearly 20 years earlier.
- Big leaps for machine learning. Ian Goodfellow and colleagues invented a new class of machine learning in 2014 called generative adversarial networks, changing the way images are created. In 2017, Google researchers unveiled the concept of transformers in their seminal paper, "Attention Is All You Need," revolutionizing the field of NLP and laying the groundwork for large language models such as ChatGPT and Dall-E.
- Rise of humanlike chatbots and dire warnings. In 2018, the research lab OpenAI, co-founded by Elon Musk, released Generative Pre-trained Transformer (GPT), paving the way for the dazzling debut of ChatGPT in November 2022. Four months later, Musk, Apple co-founder Steve Wozniak and thousands more urged a six-month moratorium on training "AI systems more powerful than GPT-4" to provide time to develop "shared safety protocols" for advanced AI systems. In May 2023, "godfather of AI" Geoffrey Hinton warned that chatbots like ChatGPT -- built on technology he helped create -- pose a risk to humanity.

What is AI? How does AI work?
Many of the tasks done in the enterprise are not automatic but require a certain amount of intelligence. What characterizes intelligence, especially in the context of work, is not simple to pin down. Broadly defined, intelligence is the capacity to acquire knowledge and apply it to achieve an outcome; the action taken is related to the particulars of the situation rather than done by rote.
Getting a machine to perform in this manner is what is generally meant by artificial intelligence. But there is no single or simple definition of AI, as noted in a definitive report published in 2016 by the U.S. government's National Science and Technology Council (NSTC).
"Some define AI loosely as a computerized system that exhibits behavior that is commonly thought of as requiring intelligence. Others define AI as a system capable of rationally solving complex problems or taking appropriate actions to achieve its goals in whatever real world circumstances it encounters," the NSTC report stated.
Moreover, what qualifies as an intelligent machine, the authors explained, is a moving target: A problem that is considered to require AI quickly becomes regarded as "routine data processing" once it is solved.
At a basic level, AI programming focuses on three cognitive skills -- learning, reasoning and self-correction:
- The learning aspect of AI programming focuses on acquiring data and creating rules for how to turn data into actionable information. The rules, called algorithms, provide computing systems with step-by-step instructions on how to complete a specific task.
- The reasoning aspect involves AI's ability to choose the most appropriate algorithm among a set of algorithms to use in a particular context.
- The self-correction aspect focuses on AI's ability to progressively tune and improve a result until it achieves the desired goal.
What are the 4 types of AI?
Modern artificial intelligence evolved from AI systems capable of simple classification and pattern recognition tasks to systems capable of using historical data to make predictions. Propelled by a revolution in deep learning -- i.e., AI that learns from data through the use of neural networks -- machine intelligence has advanced rapidly in the 21st century, bringing us such breakthrough products as self-driving cars, intelligent agents like Alexa and Siri, and humanoid conversationalists like ChatGPT.
The types of AI that exist today, including AI that can drive cars or defeat a world champion at the game of Go, also are known as narrow or weak AI. Narrow AI types have savant-like skill at certain tasks but lack general intelligence. The type of AI that demonstrates human-level intelligence and consciousness is still a work in progress.
The following are four main types of AI and a summary of their characteristics.
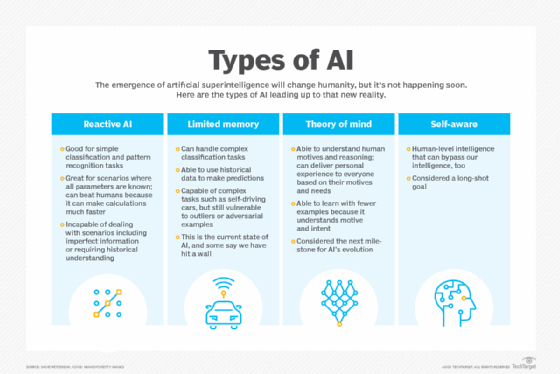
Reactive AI. Algorithms used in this early type of AI lack memory and are reactive; that is, given a specific input, the output is always the same. Machine learning models using this type of AI are effective for simple classification and pattern recognition tasks. They can consider huge chunks of data and produce a seemingly intelligent output, but they are incapable of analyzing scenarios that include imperfect information or require historical understanding.
Limited memory machines. The underlying algorithms in limited memory machines are based on our understanding of how the human brain works and are designed to imitate the way our neurons connect. This type of machine or deep learning can handle complex classification tasks and use historical data to make predictions; it also is capable of completing complex tasks, such as autonomous driving.
Despite their ability to far outdo typical human performance in certain tasks, limited memory machines are classified as having narrow intelligence because they lag behind human intelligence in other respects. They require huge amounts of training data to learn tasks humans can learn with just one example, or a few, and they are vulnerable to outliers or adversarial examples. The extraordinary language skills of conversational AI chatbots and humanlike behavior of other advanced cognitive computing systems have led to claims that AI models understand the world and therefore have achieved theory of mind. But it is generally believed current systems fall well short of human cognition.
Theory of mind. This type of as-yet hypothetical AI is defined as capable of understanding human motives and reasoning and therefore able to deliver personalized results based on an individual's motives and needs. Also referred to as artificial general intelligence, theory of mind AI can learn with fewer examples than limited memory machines. It can contextualize and generalize information and extrapolate knowledge to a broad set of problems. Emotion AI -- the ability to detect human emotions and empathize with people -- is being developed, but the current systems do not exhibit theory of mind and are very far from self-awareness, the next milestone in the evolution of AI.
Self-aware AI. This type of AI is not only aware of the mental state of other entities but is also aware of itself. Self-aware AI, or artificial superintelligence, is defined as a machine with intelligence on par with human general intelligence and in principle capable of far surpassing human cognition by creating ever more intelligent versions of itself. Currently, however, we don't know enough about how the human brain is organized to build an artificial one that is as, or more, intelligent in a general sense.
Data tsunami
Research firm IDC predicted the global datasphere -- the amount of new data that is created, captured, replicated and consumed each year -- is expected to more than double in size from 2022 to 2026, with enterprise organizations driving most of that growth. That would amount to 221 zettabytes (that is, 221 million terabytes) by 2026.
Why is AI important in the enterprise?
AI and big data play a symbiotic role in 21st-century business success. Large data sets, including a combination of structured, unstructured and semistructured data, are the raw material for yielding the in-depth business intelligence and analytics that drive improvements in existing business operations and lead to new business opportunities. Companies cannot capitalize on these vast data stores, however, without the help of AI. For example, deep learning processes large sets of data to identify subtle patterns and correlations that can give companies a competitive edge.
Simultaneously, AI relies on big data for training and generating insights. AI's ability to make meaningful predictions -- to get at the truth of a matter rather than mimic human biases -- requires not only vast stores of data but also data of high quality. Cloud computing environments have helped enable AI applications by providing the computational power needed to process and manage the required data in a scalable and flexible architecture. In addition, the cloud provides wider access to enterprise users, democratizing AI capabilities.
Forrester: 'Serious investments in AI to meet the demands of business'
Companies interested in adopting AI continue to invest in a diverse portfolio of technologies, according to a survey by Forrester Research published in May 2023. The poll of 1,981 data and analytics decision-makers worldwide showed the following statistics:
- 83% of respondents said they expect their organizations to increase spending on at least one AI technology over the next 12 months.
- 64% reported their organization is increasing spending on at least two AI technologies.
- 25% stated they are increasing spending across four or more categories.
Machine learning platforms (77%), computer and machine vision (76%) and AutoML (76%) are the main areas of increased investment.
Impact of AI in the enterprise
The value of AI to 21st-century business has been compared to the strategic value of electricity in the early 20th century when electrification transformed industries like manufacturing and created new ones such as mass communications. "AI is strategic because the scale, scope, complexity and the dynamism in business today is so extreme that humans can no longer manage it without artificial intelligence," Chris Brahm, senior advisory partner at Bain & Company, told TechTarget.
AI's biggest impact on business in the near future stems from its ability to automate and augment jobs that today are done by humans.
Labor gains realized from using AI are expected to expand upon and surpass those made by current workplace automation tools. And by analyzing vast volumes of data, AI won't simply automate work tasks but will generate the most efficient way to complete a task and adjust workflows on the fly as circumstances change.
AI is already augmenting human work in many fields, from assisting doctors in medical diagnoses to helping call center workers deal more effectively with customer queries and complaints. In security, AI is being used to automatically respond to cybersecurity threats and prioritize those that need human attention. Banks are using AI to speed up and support loan processing and to ensure compliance.
The advent of generative AI dramatically expands the type of jobs AI can automate and augment. Businesses and consumers have quickly adopted this new technology, using apps such as ChatGPT, Bard and Copilot to conduct searches, create art, compose essays, write code and make conversation.
Indeed, AI's potential to eliminate many jobs done today by humans is of major concern to workers, as described in the following sections on benefits and risks of AI.
Learn about the 10 top AI jobs in 2024
The AI revolution is changing many jobs and creating some new ones. Learn the top skills, industries and jobs that AI is making its mark on this year.
What are the benefits of AI in the enterprise?
Eighty-seven percent of surveyed organizations said they believe AI and machine learning will help them grow revenue and boost operational efficiency, according to research firm Frost & Sullivan's "Global State of AI, 2022" report.
Here are some additional key benefits of AI for businesses across industry sectors:
- Improved customer service. The ability of AI to speed up and personalize customer service is among the top benefits businesses expect to reap from the technology. Streaming media services, e-commerce companies and social media platforms, for example, use recommendation engines to generate real-time personalized suggestions for products, services or content. Voice recognition systems that streamline call routing and customer self-service benefit companies across various industries.
- Improved monitoring. AI's capacity to process data in real time means organizations can implement near-instantaneous monitoring. For example, factory floors are using image recognition software and machine learning models in quality control processes to monitor production and flag problems.
- Improved speed of business. AI enables shorter business cycles by automating internal and customer-facing processes. Reducing the time to move from one stage to the next, such as from designing a product to commercialization, results in faster ROI.
- Better quality. Organizations expect a reduction in errors and increased adherence to compliance standards by using AI on tasks previously done manually or with traditional automation tools, such as extract, transform and load software. Financial reconciliation is an example of one area where machine learning has substantially reduced costs, time and errors.
- Better talent management. Companies are using enterprise AI software to streamline the hiring process, root out bias in corporate communications and boost productivity by screening for top-tier candidates. Advances in speech recognition and other NLP tools give chatbots the ability to provide personalized service to job candidates and employees.
- Business model innovation and expansion. Digital natives such as Amazon, Airbnb, Uber and others used AI to help implement their new business models. Opportunities to remake and expand business models have also opened up for traditional companies in retail, banking, insurance and other industries as they refine their data and AI strategies.
- Industry-specific improvements. Examples include the use of AI by retailers for targeted marketing campaigns, supply chain optimization and dynamic pricing; by the pharmaceutical sector for drug discovery predictions and analysis; and by banks to use chatbots for customer service, offer personalized financial recommendations and manage fraud.
What are the risks of AI?
Some of the risks associated with AI result from the same mistakes that can sabotage any deployment of technology: inadequate planning, insufficient skill sets, lack of alignment to business goals and poor communication.
For these types of issues, companies should lean on the best practices that have guided the effective adoption of new technologies. But AI also comes with unique risks that many organizations are unequipped to deal with -- or even recognize -- due to the nature of the technology and how fast it is evolving.
One of the biggest risks to effectively using AI is worker mistrust. Professional services firm KPMG found that 61% of the respondents to its "Trust in Artificial Intelligence: Global Insights 2023" survey were either ambivalent about or unwilling to trust AI -- a mindset that can hinder AI adoption. An AI system on a factory floor that determines when a machine needs maintenance, for example, is ineffective if users are skeptical of its judgment.

Dispelling mistrust of AI is easier said than done, as shown by the current weaknesses inherent in AI technologies.
Unintentional bias. Like any data-driven tool, AI algorithms depend on the quality of data used to train the AI model. Therefore, they are subject to biases inherent in the data, leading to faulty results, socially inappropriate responses and even greater mistrust.
Unexplainable results. Unexplainable results are a significant challenge in AI systems due to their inherent black box nature. Explainability -- understanding how an algorithm reaches its conclusion -- is not always possible with AI systems, given the way they are configured with many hidden layers that self-organize their weights to create a response.
Hallucinations. An algorithm's behavior, or output, in a so-called deterministic environment can be predicted from the input. Most AI systems today are stochastic or probabilistic, meaning they rely on statistical models and techniques to generate responses that the algorithm deems probable in a given scenario. But the results are sometimes fantasy, as experienced by many users of ChatGPT, and are referred to as AI hallucinations.
What is trustworthy AI?
In her book, What You Don't Know: AI's Unseen Influence on Your Life and How to Take Back Control, Cortnie Abercrombie, CEO and founder of AI ethics nonprofit AI Truth and former AI and data science strategist at IBM, laid out 10 tenets of trustworthy AI: humane, consensual, transparent, accessible, agency-imbuing, explainable, private and secure, fair and quality data, accountable, traceable, feedback-incorporating, governed and rectifiable.
Risks stemming from AI can't be eliminated, but they can be managed. Adopting an AI code of ethics can increase the transparency of AI models, thereby minimizing the chances of AI systems unintentionally reinforcing harmful biases, making unclear decisions or causing unwanted outcomes.
In addition to the technology risks inherent in AI technologies, enterprises must manage external risks -- such as the use of AI by hackers and other bad actors to evade enterprise defenses -- and internal risks created by shadow AI programs and lack of AI governance.
Also, despite the increasing ease and sophistication of AIOps platforms and other prepackaged AI tools, traditional companies might still find integrating AI into their operations an uphill battle due to legacy systems, data challenges, skills gaps and cultural resistance, among other challenges.
Current business applications of AI
A Google search for "AI use cases" turns up millions of results, an indication of the many enterprise applications of AI. AI use cases span industries, from financial services -- an early adopter -- to healthcare, education, marketing and retail. AI has made its way into every business department, from marketing, finance and HR to IT and business operations. Additionally, the use cases incorporate a range of AI applications: natural language generation tools used in customer service, deep learning platforms used in automated driving and facial recognition tools used by law enforcement, among others.
Here is a sampling of how various industries and business departments are using AI.
Financial services. The financial sector uses AI to process vast amounts of data to improve almost every aspect of business, including risk assessment, fraud detection and algorithmic trading. The industry also automates and personalizes customer service through the use of chatbots and virtual assistants, including robo-advisors designed to provide investment and portfolio advice.
Manufacturing. Collaborative robots, aka cobots, are working on assembly lines and in warehouses alongside humans, functioning as an extra set of hands. Other AI use cases in manufacturing involve using AI to predict maintenance requirements and employing machine learning algorithms to identify purchasing patterns for predicting product demand in production planning.
Agriculture. The agriculture industry is using AI to yield healthier crops, reduce workloads and organize data.
Law. The document-intensive legal industry is using AI to save time and improve client service. Law firms are deploying machine learning to mine data and predict outcomes; they are also using computer vision to classify and extract information from documents, and NLP to interpret requests for information.
Education. In addition to automating the tedious process of grading exams, AI is being used to assess students and adapt curricula to their needs, paving the way for personalized learning.
IT service management and cybersecurity. IT organizations apply machine learning to ITSM data to gain a better understanding of their infrastructure and processes. They use the named entity recognition component of natural language processing for text mining, information retrieval and document classification. AI techniques are applied to multiple aspects of cybersecurity, including anomaly detection, solving the false-positive problem and conducting behavioral threat analytics.
Marketing. Marketing departments use a range of AI tools, including chatbots and virtual assistants for customer support, recommendation engines for analyzing customer data and generating personalized suggestions, and sentiment analysis for brand monitoring.
How have AI use cases evolved?
The rapid advances in large language models (LLMs) -- i.e., models with billions or even trillions of parameters -- mark a new era in business applications in which generative AI models can write engaging text, generate photorealistic images and conjure up movie scripts on the fly. Disruptive use cases for this emerging technology include writing email responses, profiles, resumes and term papers; designing physical products and buildings; and optimizing new chip designs.
As companies deal with aftermath of the coronavirus pandemic, AI is also being used to better understand how businesses can adapt and remain profitable in the face of unforeseen disruptions. Applications of AI in this realm involve scenario analysis, hypothesis testing and assumption testing. But model building will have to become nimbler and more iterative to get the most out of AI applications by tapping the knowledge of employees, noted AI expert Arijit Sengupta, who added that getting end-user feedback is critical in uncertain times because end users will know things that haven't yet surfaced in the data.
AI adoption in the enterprise
AI adoption in business has more than doubled in the past five years, according to the annual "McKinsey Global Survey on AI" report: Adoption has risen from 20% of respondents in 2017 who reported using AI in at least one business area, to 50% in 2022. But the 2022 survey's findings, published in December, tell a nuanced story:
- While adoption is 2.5 times higher than in 2017, it has leveled off in the past few years.
- The average number of AI capabilities used by organizations (e.g., robotic process automation, NLP, computer vision, virtual agents, deep learning) has doubled to 3.8 in 2022, up from 1.9 capabilities in 2018.
- Value from AI has evolved: Whereas manufacturing and risk management were the top functions benefiting from AI in 2018, the biggest revenue gains from AI cited in 2022 were in marketing and sales, product development, and strategy and corporate finance. The biggest AI cost savings were in supply chain management.
- Companies with the best financial returns from AI -- so-called AI high performers -- "continue to pull ahead of competitors." Investments in AI by these companies are larger, they use increasingly advanced practices to scale AI and they have an easier time attracting talent in the tight labor market for AI.
The "IBM Global AI Adoption Index 2022" poll, based on research conducted by Morning Consult on behalf of IBM, reported that the worldwide AI adoption rate had grown to 35%, a four-point increase from 2021. Key findings from the survey of IT decision-makers at 7,502 businesses included the following:
- Workplace augmentation. Nearly one-third (30%) of respondents said employees at their organization are saving time with new AI and automation software and tools.
- Sustainability. About two-thirds (66%) of companies said they are either using or planning to use AI to address their sustainability goals.
- Use cases. Around half of organizations are seeing benefits from using AI to automate IT, business or network processes (54%); improve IT or network performance (53%); and improve experiences for customers (48%).
Here are the top five hindrances to successful AI adoption cited by survey respondents:
- Limited AI skills, expertise or knowledge (34%).
- Price too high (29%).
- Lack of tools or platforms to develop models (25%).
- Projects are too complex or difficult to integrate and scale (24%).
- Too much data complexity (24%).
Also, a majority of organizations reported they have not taken these steps to ensure their AI is trustworthy and responsible: reducing bias (74%); tracking performance variations and model drift (68%); and making sure they can explain AI-powered decisions (61%).

Steps for implementing artificial intelligence in the enterprise
AI comes in many forms: machine learning, deep learning, predictive analytics, NLP, computer vision and automation. Deriving value from AI's many technologies requires companies to address issues related to people, processes and technology.
As with any emerging technology, the rules of implementation are still being written. Industry leaders in AI emphasize that an experimental mindset will yield better results than a "big bang" approach. Start with a hypothesis, followed by testing and rigorous measurement of results -- and iterate. Here is a list of 10 AI implementation steps to follow:
- Build data fluency.
- Define your primary business drivers for AI.
- Identify areas of opportunity.
- Evaluate your internal capabilities.
- Identify suitable candidates.
- Pilot an AI project.
- Establish a baseline understanding.
- Scale incrementally.
- Bring overall AI capabilities to maturity.
- Continuously improve AI models and processes.
Enterprise AI vendors and tool market
The enterprise AI vendor and tool ecosystem addresses multiple AI-related capabilities.
The large cloud AI platforms from AWS, Google, IBM and Microsoft each come with tools for developing and deploying AI apps. These are a good fit if your enterprise already has a large cloud presence on one platform.
Products from the big cloud providers generally fall into two tiers: data science and machine learning (DSML) platforms targeted at data scientists, and a second set of low-code modules more suited for a wider range of users.
For example, Microsoft Azure AI provides comprehensive tooling, while Azure Cognitive Services provides pre-built AI modules.
AWS similarly has Amazon SageMaker, a managed machine learning service in its public cloud that developers can use to build a production-ready AI pipeline, plus a set of AI services that is advertised as not requiring machine learning experience.
IBM's large portfolio of artificial intelligence products and services is mainly built on Watson technology and supports both DSML platforms and pre-built modules.
Google brands all its AI offerings for developers and business users under Google AI. Its MakerSuite product for building generative AI prototypes does not require machine learning expertise.
Several of the available DSML platforms provide a comprehensive set of tools for creating, deploying and managing AI models. MLOps platforms, in distinction, are more focused on streamlining the process of putting AI models into production and then maintaining and monitoring them over time.
Top DSML platform vendors include Databricks, Dataiku, DataRobot, C3 AI, H2O.ai and RapidMiner. Top MLOps vendors include Cnvrg.io, Domino Data Lab and Iguazio; Kubeflow, an open source technology for managing machine learning workflows on Kubernetes, is also available.
Although many platforms specialize in one kind of capability, it should be noted that most of the larger players are branching out to support the entire spectrum of AI development, deployment and monitoring capabilities.
AI trends
It is hard to overstate the scope of development being done on artificial intelligence by vendors, governments and research institutions -- and how quickly the field is changing. The rapid evolution of algorithms accounts for many recent advancements, notably the new -- and disruptive -- AI large language models that are redefining the modern search engine.

Equally impressive and worthy of enterprise attention are the spate of new tools designed to automate the development and deployment of AI. Moreover, AI's push into new domains such as conceptual design, small devices and multimodal applications will expand AI's repertoire and usher in game-changing abilities for many more industries.
To take full advantage of these trends, IT and business leaders must develop a strategy for aligning AI with employee interests and with business goals. Streamlining and democratizing access to AI is essential, as is an enterprise-wide commitment to creating responsible AI. A significant increase in AI regulations and laws worldwide is coming amid rising concerns about the impact of AI on society. Enterprise leaders must stay abreast of them.
The following are some of the top AI and machine learning trends:
- AutoML. Automated machine learning is getting better at labeling data and automatic tuning of neural net architectures. By automating the work of selecting and tuning a neural network model, AI will become cheaper and new models will take less time to reach market.
- AI-enabled conceptual design. AI is being trained to play a role in fashion, architecture, design and other creative fields. AI models such as Dall-E, for example, are able to generate conceptual designs of something entirely new from a text description.
- Multimodal learning. AI is getting better at supporting multiple modalities such as text, vision, speech and IoT sensor data in a single machine learning model.
- AI-based cybersecurity. AI is helping organizations detect and defend against threats, which in turn are increasing in velocity and complexity due to AI automation.
- Improved language modeling. The November 2022 debut of ChatGPT marked a new era in language modeling and ignited many new use cases in industries ranging from marketing and customer support to education and legal services.
- Computer vision. Less expensive cameras and new AI are creating opportunities to automate processes that previously required humans to inspect and interpret objects. Although challenges abound, computer vision implementations will be an ever more important trend in the near future.
The future of artificial intelligence
One of the characteristics that has set us humans apart over our several-hundred-thousand-year history on Earth is a unique reliance on tools and a determination to improve upon the tools we invent. Once we figured out how to make AI work, it was inevitable that AI tools would become increasingly intelligent. What is the future of AI? It will be intertwined with the future of everything we do. Indeed, it will not be long before AI's novelty in the realm of work will be no greater than that of a hammer or plow.
However, AI-infused tools are qualitatively separate from all the tools of the past -- which include beasts of burden as well as machines. We can talk to them, and they talk back. Because they understand us, they have rapidly invaded our personal space, answering our questions, solving our problems and, of course, doing ever more of our work.
This synergy is not likely to stop anytime soon. Arguably, the very distinction between what is human intelligence and what is artificial will probably evaporate. This blurring between human and artificial intelligence is occurring because of other trends in technology, which incidentally have been spurred by AI. These include brain-machine interfaces that skip the requirement for verbal communication altogether, robotics that give machines all the capabilities of human action and -- perhaps most exciting -- a deeper understanding of the physical basis of human intelligence thanks to new approaches to unravel the wiring diagrams of actual brains.
Ultimately, our future then is one in which the enhancement of intelligence might be bidirectional, making both our machines -- and us -- more intelligent. That is, unless machines reach a superhuman level of intelligence and humanity becomes just another interesting experiment in the evolution of intelligence.
Latest AI technology defined
Artificial intelligence as a service
Artificial intelligence as a service, or AIaaS, is the third-party offering of artificial intelligence (AI) outsourcing that enables individuals and companies to experiment with AI.
Augmented intelligence
Augmented intelligence is the use of technology to enhance a human's ability to execute tasks, perform analysis and make decisions.
Computational linguistics
Computational linguistics (CL) is the application of computer science to the analysis and comprehension of written and spoken language.
Lemmatization
Lemmatization is the process of grouping together different inflected forms of the same word that's used in computational linguistics, natural language processing and chatbots.
Natural language generation
Natural language generation is the use of artificial intelligence programming to produce written or spoken narratives from a data set.
Neuromorphic computing
Neuromorphic computing is a method of computer engineering in which elements of a computer are modeled after systems in the human brain and nervous system.
Linda Tucci is an executive industry editor at TechTarget Editorial. A technology writer for 20 years, she focuses on the CIO role, business transformation and AI technologies.
George Lawton also contributed to this article.
Dig Deeper on AI business strategies
-
![]()
What is artificial intelligence (AI)? Everything you need to know
By: Nicole Laskowski
-
![]()
Artificial intelligence vs. human intelligence: Differences explained
By: Michael Bennett
-
![]()
AI vs. machine learning vs. deep learning: Key differences
By: David Petersson
-
![]()
4 main types of artificial intelligence: Explained
By: Alexander Gillis



