
Key considerations for operationalizing machine learning
Once a machine learning model is trained, developers need to operationalize it. This turns out to be a significant challenge for many enterprises.

Training a machine learning model is important, but you need to get the model into a production environment working on real-world data to get real-world value from it. In the lingo of artificial intelligence, putting machine learning models into real-world environments where they are acting on real-world data and providing real-world predictions is called "operationalizing" the machine learning models.
Why don't we simply say we're "deploying" an AI model or putting it into production? There's a simple reason for the terminology difference. Once a model has been trained, it needs to be applied to a particular problem, but you can apply that model in any of a number of ways. The model can sit on a desktop machine providing results on demand, or it can sit on the edge in a mobile device, or it can sit in a cloud or server environment providing results in a wide range of use cases.
Each one of these places where the model operates can be considered a separate deployment, so simply saying the model is deployed doesn't give us enough information. This terminology difference is not the only thing that is substantially different when operationalizing machine learning models.
Data-centric machine learning operationalization vs. functionality-centric application deployment
When working with traditional application functionality, we think about code and development environments. We work through developer operations (DevOps) capabilities and make sure the code is functional and tested to the levels required. However, very little of this is relevant to the AI universe.
In AI, the only code deals with aspects of implementing the machine learning algorithm, code to interact with the model, and code involved in manipulating data. But all this code in reality doesn't do much. The data is what ultimately controls the way that machine learning systems behave. The machine learning model is simply the collected experience learned and trained over time based on a particular algorithmic approach. We collect this experience in the training phase of an AI project. Once we've sufficiently trained the system to acceptable performance levels, we then enter the inference phase where we take the model we've trained and apply it to new, unknown data. So, operationalizing machine learning really is just putting the model into places where it can make inferences on real data.
The data-centricity of machine learning means that even if all the code passes quality assurance checks, works as tested, and is 100% certain to be bug-free, the entire machine learning-based system can still fail because the model itself performs poorly. The model could have been trained on bad data, or the real-world data could be bad, or there might be some other mismatch between the assumptions from the model training and the real world in which the machine learning model is operating. From this perspective, simply testing functionality or doing anything that's focused on application code or development-centric technology is not particularly relevant to machine learning projects. We need to focus on data quality and data management to be relevant for AI operationalization.
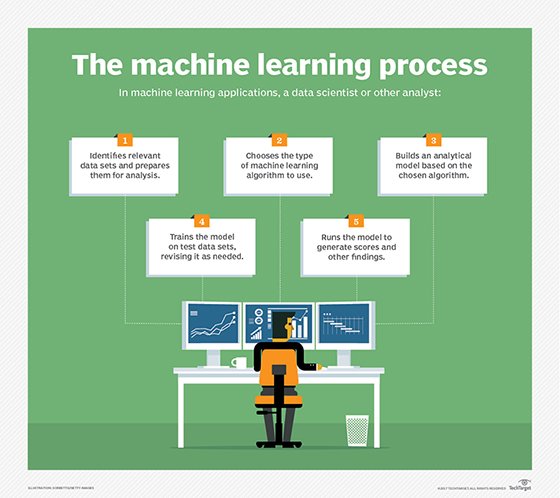
Machine learning-focused operationalization challenges
As detailed above, machine learning models don't follow the same design, build, test, deploy and manage phases of traditional application development projects. There are really only two phases for machine learning models: the training phase and the inference phase. A model ready to be used in inference can be placed anywhere that the model needs to provide predictions. This means it can be placed in a mobile app, on a server, on an edge device, in the cloud, on a desktop or even in a web browser with JavaScript. Each one of these environments is a completely different code and application development environment, yet it's the very same model that's being used for each of these environments, which presents one of the central tensions in operationalizing machine learning models.
The primary concern during the machine learning model training phase is the identification of relevant training data, the preparation and selection of that data, algorithm selection, algorithm tuning, hyperparameter optimization and the resource-intensive machine learning model training itself that could take hours, days, or even weeks to complete. Since data quality has a significant impact on the outcome of machine learning model quality, data scientists and data engineers focus their time on the creation and management of clean, well-labeled data, and the validation and testing of the trained model to make sure that it can generalize without too much overfitting of training data or underfitting of test data.
On the other hand, the primary concern during the inference phase of an AI project is on whether or not the trained model is generalizing properly to real-world data. If so, then it can be used with little adjustment. However, if the model produces unsatisfactory results, the AI team needs to focus their time on making adjustments to the model, creating new training data sets, changing hyperparameter settings, and otherwise iterating the model. In the inference phase, the AI team can look at how the real world diverges from the training environment and determine if the use cases for the machine learning model are broader than originally specified with the training data. The training phase is basically happening in the organizational laboratory, while the inference phase is happening in the real-world environment.
Not surprisingly, it's in the real world where things are messy and complicated. Data in the real world is rarely clean or well ordered. The real-world behavior of users might differ from the assumptions we made when selecting training data. Usage patterns on one device or system might differ from usage patterns on the systems where we trained the model. The real world might start diverging from the training data over time, resulting in models that once worked very well becoming less satisfactory over time.
Differences in machine learning environments
There are also significant differences between the tools used to train and operationalize machine learning models. As mentioned earlier, machine learning models might take hours, days, weeks or even longer to train. The reason for this is that to configure the millions of connections in deep learning neural networks, and even sophisticated decision trees and other algorithms, is computationally intensive.
The usage of math-optimized chips such as GPUs or the more recently developed neural network-optimized chips such as tensor processing units (TPUs) and field programmable gate arrays (FPGAs) are helping to make the training phase more efficient. Training data sets also can be large, heading into the terabytes or even petabytes for particularly complex scenarios or models requiring high accuracy.
However, once the model is trained, running it doesn't require significant resources. Models can occupy significantly less space than the data that they used for training, and can execute in rapid time on even commodity CPUs. While there are models that benefit from GPUs or optimized chipsets in inference phase, especially with regard to image and facial recognition applications, GPUs might not be needed in inference phase.
Furthermore, while the models might have been trained in an enterprise server or cloud-based environment, the model itself might be operationalized on the edge in a mobile or IoT device or be used as a microservice in a cloud environment. We could be using a machine learning model in a device deployed at the edge, in a mobile application that can operate disconnected from the internet, in a cloud-based always-on setting, or in a large enterprise server system with private, highly regulated or classified content. We also could be using it in desktop applications, or in autonomous vehicles, or in distributed applications, or really anywhere that a model can provide value. The very same model can be deployed in a wide range of places, and so might need to be small and compact to fit resource-constrained endpoint requirements.
While the specifics of where the models are used might be important to application developers, it's actually not of primary concern for data scientists. Data scientists building and training models are focused on whether they are providing predictive accuracy, not on how the model will actually be used. The model needs to provide the right results within the constraints of the system, not be optimized for any particular end-point deployment. In many ways, the models that are built by the data scientists are implementation neutral. They are often instantiated as simple Java or Python objects along with configuration parameters. The specific choices of operationalizing machine learning have mostly to do with efficiency, platforms already in use, skills of the developers and integration into the application development lifecycle. As a result, these models can be placed anywhere that the Java, Python, C#, or other language will operate.
Machine learning models don't provide guarantees -- they provide probabilities
Machine learning models are probabilistic by nature. When a machine learning model provides a result, it actually provides a prediction. It is almost guaranteed that machine learning models will not produce a 100% certain result. Given that, how do applications that utilize machine learning models deal with the uncertainty? When operationalizing machine learning, developers need to build these systems with fallbacks for when the systems don't provide results with acceptable levels of certainty. Developers might set thresholds by which they will accept answers, and provide some alternate functionality if the model doesn't meet those thresholds.
In addition, developers need to be concerned with making sure that the incoming data matches the required format, level of quality and cleanliness as required by the model. For example, an image recognition system might have been trained on high-quality, well-formatted, well-labeled images in well-lit situations. However, real-world images might need to be cropped or otherwise manipulated, might be low resolution, be taken in bad lighting, corrupted, improperly aligned or otherwise impaired. The developers need to deal with this data to either improve the images to the required standards or reject them prior to use within the model.
The punchline of all this discussion of operationalizing machine learning is that the tools, data and practices of building and using models are not the same as the tools, data and practices of the application development environment. Understanding the unique requirements of operationalizing AI will lead to AI project success.
Dig Deeper on AI infrastructure
-
![]()
Teradata ClearScape Analytics update targets ROI on AI, ML
By: Eric Avidon
-
![]()
What is a validation set? How is it different from test, train data sets?
By: Alexander Gillis
-
![]()
How to build a machine learning model in 7 steps
By: Emily Foster
-
![]()
Informatica adds AI assistant, GenAI development interface
By: Eric Avidon



