Choosing between a rule-based vs. machine learning system
Deciding between a rule-based vs. machine learning system comes down to complexity and organizational needs. Compare the advantages, drawbacks and use cases for each AI approach.
When implementing AI systems, choosing between a rule-based vs. machine learning architecture is critical to an application's usability, compatibility and efficiency.
Getting output from a rule-based AI system can be simple and nearly immediate, but machine learning systems can handle more complex tasks with greater adaptability. Enterprises should understand the core differences between rule-based and machine learning systems, including their benefits and limitations, before taking advantage of either.
What is a rule-based system?
In AI, rule-based systems are a basic type of model that uses a set of prewritten rules to make decisions and solve problems. Developers create rules based on human expert knowledge that enable the system to process input data and produce a result.
To build a rule-based system, a developer first creates a list of rules and facts for the system. An inference engine then measures the information given against these rules. Here, human knowledge is encoded as rules in the form of if-then statements. The system follows the rules set and only performs the programmed functions.
For example, a rule-based algorithm or platform could measure a bank customer's personal and financial information against a programmed set of levels. If the numbers match, the bank grants the applicant a home loan.
Advantages and downsides of rule-based systems
Organizations often use rule-based systems because of the following benefits:
- Accuracy. Rule-based systems operate by cause and effect and only within their rule set. Thus, the system's rules act as guardrails to ensure precision and accuracy.
- Ease of use. Rule-based systems require only small amounts of simple data to perform tasks and repetitive processes. This makes them easy for developers to create, use and debug.
- Speed. With the proper training, rule-based systems can make informed decisions quickly and efficiently, as there is no room for interpretation or growth. Their limited parameters ensure that responses come as fast as possible.
But, because of their simplistic nature, rule-based systems often fall short in the following ways:
- Limited scope. Rule-based systems are exact and do not have learning capabilities, which limits them to working only within the confines of their original programming. Including too many rules can slow down a system and introduce complexity.
- Immutability. By nature, rule-based systems do not change and are unscalable. Altering existing rules or incorporating new ones can introduce time-consuming and expensive complications.
- Restricted intelligence. A rule-based system is only as good as the rules set by its developers and cannot make decisions independent of those rules. This means the system can only act based on its explicit programming and will reflect any flaws or oversights in the original rule set.
What is a machine learning system?
Machine learning is a type of AI that enables applications to predict outcomes without being explicitly programmed to do so. Machine learning algorithms independently detect and analyze data patterns and modify their behavior accordingly to predict new output.
To create a machine learning system, developers select an appropriate AI model and present it with a large data set. The chosen algorithm analyzes the data set and determines relationships within that data.
The logic within machine learning systems is embedded in the algorithm, not coded by a human. As the name suggests, a machine learning model autonomously "learns" from its training data, creating a direct relationship between data inferences and future data outputs.
Advantages and downsides of machine learning systems
Machine learning systems provide the following benefits to organizations:
- Adaptability. Machine learning systems adjust without human intervention as new data is presented to make informed decisions and predictions through continuous learning. This makes them well suited to addressing dynamic problems in fast-changing environments.
- Self-learning. Machine learning systems adapt in response to the patterns and relationships in their input data, enabling models to define their own rules that take into account a wide range of variables. This capability makes machine learning a good choice for tackling complex processes that include multiple factors, rules and patterns that change over time.
- Scalability. As projects and environments grow, machine learning systems can scale and adapt accordingly with new data, infrastructure resources and algorithms. For example, an organization could upgrade a simple classifier to a neural network by expanding its training data set and underlying infrastructure.
Though machine learning systems can tackle many issues, they also come with the following downsides:
- Dependence on quality of training data. Because data quality directly affects model quality, machine learning systems must be thoroughly trained on historical and relevant data to make well-informed decisions and predictions. However, building a sufficiently large and relevant data set can be a resource-intensive and time-consuming process.
- Complexity. Although machine learning systems can handle larger, more complex tasks and environments than rule-based systems, they also require greater technical expertise from teams to develop effective applications. Tasks such as writing machine learning algorithms, identifying useful data and monitoring models in production warrant a data science team and require properly trained employees.
- Limited adaptability. Machine learning systems can adjust and grow, but they cannot adapt to situations or problems outside the realm they are trained for. These systems lack the human intuition to come to conclusions outside their range of knowledge.
Choosing between rule-based vs. machine learning systems
Rule-based AI and machine learning differ in both the type of logic they use to operate and the level of human intervention they require. For rule-based systems, the system's decision logic is instilled at the beginning, with little flexibility after deployment. Machine learning systems, on the other hand, can learn continuously without human direction.
Given these differences in learning methods, the choice between a rule-based or machine learning system comes down to organizational needs. Different types of AI can take different types of actions and produce different analyses or insights.
Applying machine learning and rule-based systems
The choice between a rule-based vs. machine learning system depends on how strict parameters must be, requirements around efficiency and training costs, and whether a data science team or an algorithm will create the rules.
Machine learning can handle complex and intensive issues in relatively variable environments, whereas rule-based AI systems are easier to interpret and promote precision. In addition, the adaptability and speed of machine learning systems comes at a cost. There is an advanced level of commitment with machine learning, as algorithms require large amounts of data to be effective.
Training on this data can take extended periods of time, so taking a rule-based approach might make more sense for simpler tasks. Rule-based systems work well for scenarios that don't involve highly complicated decisions or massive amounts of complex data.
Limitations to consider
Though rule-based systems are typically not complex by nature, adding more rules and mitigating factors can introduce contradictions and overlap.
Taking the example of average income needed to be approved for a home loan, a rule-based system would have data scientists create a rule, such as requiring a monthly income of three times the estimated monthly mortgage payment. However, it's never that simple in large AI applications: The more modifications necessary, the more complicated rule-based systems can become.
In the above example, these modifications could include anything from factoring in an applicant's location to accounting for an economic downturn. These new rules significantly increase the amount of time and planning originally anticipated. Although this increase in foundational work enables greater adaptability, it also takes more time. Therefore, mitigating the limiting factors can also decrease ease of use.
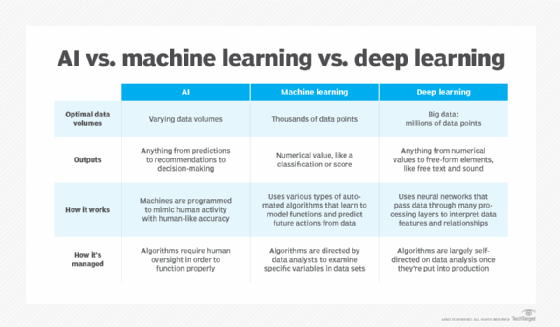
Turning to machine learning models makes sense when the modifications in a rule-based system become overbearing. Machine learning excels in constantly changing environments, as it is scalable and mutable.
Creating an algorithm, training it on relevant data sets and teaching it to identify patterns and relationships requires a greater initial investment. But the resulting model can handle more complexity than a rule-based system.
To continue with the above example, a machine learning system could use backpropagation for optimization to find the rule for approval as it learns from data. Thus, the model could ultimately arrive at a more nuanced rule that takes into account an applicant's income, credit history and location.
If the model is attempting to discover new or rare events, such as fraud protection, the field from which examples can be harvested will be limited to start. Not having enough labeled data will hinder the model's performance.
Editor's note: Joseph M. Carew originally wrote this tip, and Emily Foster updated and expanded it.






