How to build a machine learning model in 7 steps
Building a machine learning model is a multistep process involving data collection and preparation, training, evaluation, and ongoing iteration. Follow these steps to get started.
Even for those with experience in machine learning, building an AI model can be complex, requiring diligence, experimentation and creativity.
But at a high level, the process of designing, deploying and managing a machine learning model typically follows a general pattern. By learning about and following these steps, you'll develop a better understanding of the model-building process and best practices for guiding your project.
The right approach starts with identifying data needs and results in a reliable, maintainable final model. In between, you'll work through the stages of data discovery and cleaning, followed by model training, building and iteration.
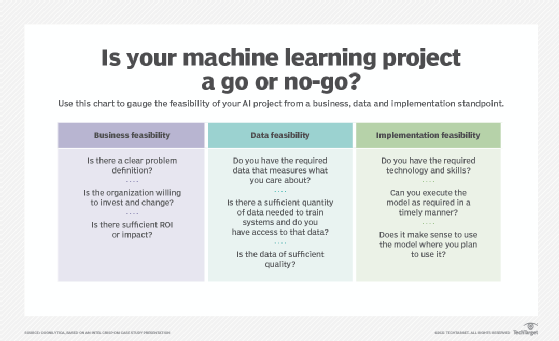
Step 1. Understand the business problem and define success criteria
The first phase of any machine learning project is developing an understanding of the business requirements: You need to know what problem you're trying to solve before attempting to solve it.
To start, work with the project owner to establish the project's objectives and requirements. The goal is to convert this knowledge into a suitable problem definition for the machine learning project and devise a preliminary plan to achieve the project's objectives.
Key questions to answer include the following:
- What's the business objective and which parts of achieving that goal require a machine learning approach?
- What is the heuristic option -- in other words, the quick-and-dirty approach that doesn't require machine learning -- and how much better than the heuristic does the model need to be?
- What type of algorithm is the best fit for the problem at hand -- for example, classification, regression or clustering?
- Have the relevant teams addressed all the necessary technical, business and deployment issues?
- What are the project's defined success criteria and how will the organization measure the model's benefits?
- How can teams stage the project in iterative sprints?
- Are there requirements for transparency, explainability or bias reduction?
- What are the ethical considerations?
- What are the acceptable parameters for accuracy, precision and confusion matrix values?
- What are the expected inputs and outputs?
Setting specific, quantifiable goals will help you realize measurable ROI from your machine learning project, rather than implementing a proof of concept that will be tossed aside later.
These goals should relate to the business objectives, not just machine learning. Although you can include typical machine learning metrics such as precision, accuracy, recall and mean squared error, it's essential to prioritize specific, business-relevant KPIs.
Step 2. Understand and identify data needs
After establishing the business case for your machine learning project, the next step is to determine what data is necessary to build the model. Machine learning models generalize from their training data, applying the knowledge acquired in the training process to new data to make predictions.
A lack of data will prevent you from building the model, but access to data alone isn't enough: Useful data must be clean, relevant and well structured. To identify your data needs and determine whether the data is in proper shape for model ingestion, focus on data identification, initial collection, requirements, quality identification, insights and aspects worth further investigation.
To get a handle on the quantity, quality and types of data you'll need, consider these key questions:
- What type and quantity of data is necessary for the machine learning project?
- What are the necessary data sources and locations?
- What is the current quantity and quality of training data?
- How will you split the data collected into test and training sets?
- If you're working on a supervised learning task, how will you label data?
- Can you use a pre-trained machine learning model?
- Are there any special requirements, such as the need to access real-time data on edge devices or other difficult-to-reach places?
It's also crucial to know how the model will operate on real-world data once deployed. For example, will the model be used offline? Will it operate in batch mode on data that's fed in and processed asynchronously? Or will it be used in real time, operating with high performance requirements to provide instant results? The answers to these questions will inform what sort of data is needed and data access requirements.
In addition, determine whether you will train the model once, in iterations with versions deployed periodically or in real time. Real-time training imposes many requirements on data that might not be feasible for some setups.
Finally, during this phase of the AI project, it's important to determine whether any differences exist between real-world and training data or between test and training data. If so, decide what approach you will take to validate and evaluate the model's performance.

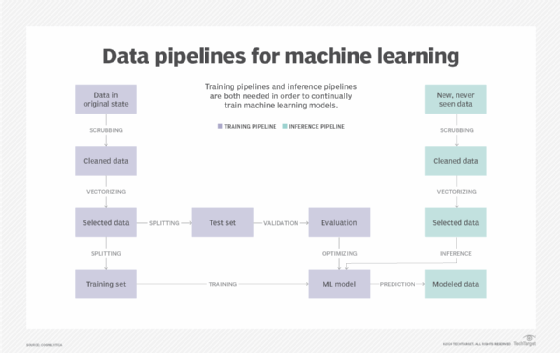
Step 3. Collect, clean and prepare the data for model training
After identifying the appropriate data, the next step is to shape that data so that it can be used to train the model.
Data preparation tasks include data collection, cleansing, aggregation, augmentation, labeling, normalization and transformation, as well as any other activities for structured, unstructured and semistructured data. Data preparation and cleansing tasks can take a substantial amount of time, but because machine learning models are so dependent on data, it's well worth the effort.
Steps you might undertake during data preparation, collection and cleansing include the following:
- Collect data from various sources.
- Standardize data formats and normalize data across different sources.
- Replace incorrect or missing data.
- Enhance and augment data, possibly by using third-party data or multiplying image-based data sets if the core data set is insufficient for training.
- Add dimensions with pre-calculated amounts and aggregate information as needed.
- Remove extraneous and redundant information, known as deduplication, and remove irrelevant data.
- Reduce noise and remove ambiguity.
- Consider anonymizing personal or otherwise sensitive data.
- Sample data from large data sets.
- Select features that identify the most important dimensions and, if necessary, reduce dimensions using a variety of techniques.
- Split data into training, test and validation sets.
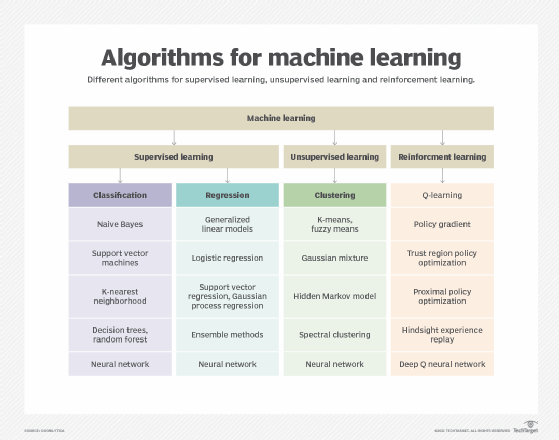
Step 4. Determine the model's features and train it
Once the data is in usable shape and you know the problem you're trying to solve, it's time to train the model to learn from the quality data by applying a range of techniques and algorithms. This phase requires selecting and applying model techniques and algorithms; setting and adjusting hyperparameters; training and validating the model; developing and testing ensemble models, if needed; and optimizing the model.
To accomplish all that, this stage often includes the following actions:
- Select the right algorithm for your learning objective and data requirements. For example, linear regression is a popular option for mapping correlations between two variables in a data set.
- Configure and tune hyperparameters for optimal performance and determine a method of iteration such as learning rate to attain the best hyperparameters.
- Identify features that provide the best results.
- Determine whether model explainability or interpretability is required.
- Develop ensemble models for improved performance.
- Compare the performance of different model versions.
- Identify requirements for the model's operation and deployment.
Evaluate the resulting model to determine whether it meets the business and operational requirements.
Step 5. Evaluate the model's performance and establish benchmarks
Evaluating a model's performance encompasses confusion matrix calculations, business KPIs, machine learning metrics, model quality measurements and a final determination of whether the model can meet the established business goals.
During the model evaluation process, perform the following assessments:
- Evaluate the model using a validation data set.
- Determine confusion matrix values for classification problems.
- Identify methods for K-fold cross-validation, if using that approach.
- Further tune hyperparameters for optimal performance.
- Compare the machine learning model to the baseline model or heuristic.
Consider model evaluation to be the quality assurance of machine learning. Adequately evaluating model performance against metrics and requirements helps you understand how the model will work in the real world.

Step 6. Deploy the model and monitor its performance in production
When you're confident that the machine learning model can work in the real world, it's time to see how it actually operates.
This process, known as operationalizing the model, includes the following steps:
- Deploy the model with a means of continually measuring and monitoring its performance.
- Develop a baseline or benchmark against which you can measure future iterations of the model.
- Continuously iterate on different aspects of the model to improve overall performance.
Operationalization considerations include model versioning, iteration, deployment, monitoring, and staging in development and production environments.
Model operationalization might include deployment scenarios in a cloud environment; at the edge; in an on-premises or closed environment; or within a closed, controlled group. Depending on the requirements, model operationalization can range from generating a report to a more complex, multi-endpoint deployment.
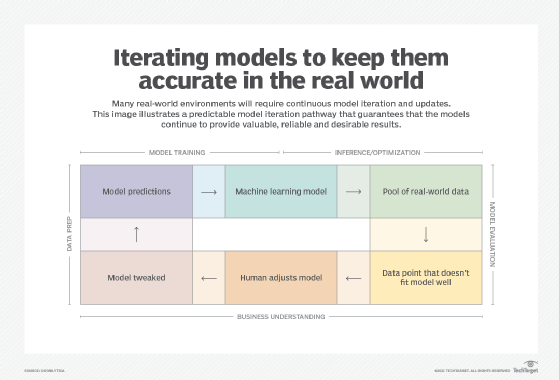
Step 7. Iterate and adjust the model in production
It's often said that the formula for success when implementing technologies is to start small, think big and iterate often.
Even after a machine learning model is in production and you're continuously monitoring its performance, you're not done. Business requirements, technology capabilities and real-world data all change in unexpected ways, potentially creating new requirements for deploying the model onto different endpoints or in new systems.
Repeat the process and make improvements in time for the next iteration. When evaluating and adjusting a machine learning model in production, consider the following:
- Incorporate the next requirements for the model's functionality.
- Expand model training to encompass greater capabilities.
- Improve model performance and accuracy, including operational performance.
- Determine operational requirements for different deployments.
- Address model or data drift, which can cause changes in performance due to real-world data changes.
Reflect on what has worked in your model, what needs work and what's a work in progress. The surefire way to achieve success when building a machine learning model is to continuously look for improvements and better ways to meet evolving business requirements.
Editor's note: Kathleen Walch and Ronald Schmelzer originally wrote this feature, and Emily Foster updated and expanded it.






