
microworks - Fotolia
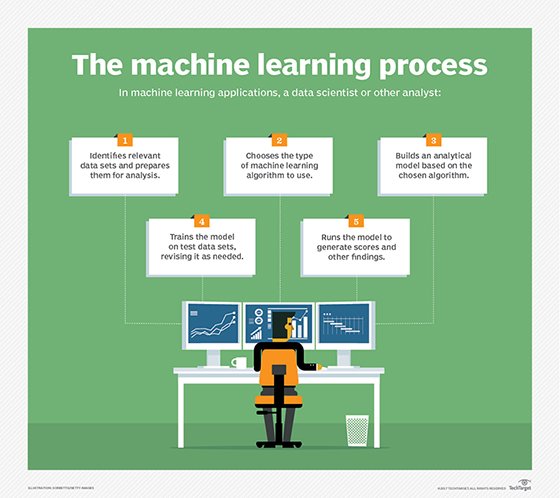
Getting to machine learning in production takes focus
Bridging the gap between training and production is one of the biggest machine learning development hurdles enterprises face, but some are finding ways to streamline the process.

Data scientists that build AI models and data engineers that deploy machine learning in production work in two different realms. This makes it hard to efficiently bring a new predictive model into production.
But some enterprises are finding ways to work around this problem. At the Flink Forward conference in San Francisco, engineers at Comcast and Capital One described how they are using Apache Flink to help bridge this gap to speed the deployment of new AI algorithms.
Version everything
The tools used by data scientists and engineers can differ in subtle ways. That leads to problems replicating good AI models in production.
Comcast is experimenting with versioning all the artifacts that go into developing and deploying AI models. This includes machine learning data models, model features and code running machine learning predictions. All the components are stored in GitHub, which makes it possible to tie together models developed by data scientists and code deployed by engineers.
"This ensures that what we put into production and feature engineering are consistent," said Dave Torok, senior enterprise architect at Comcast.
At the moment, this process is not fully automated. However, the goal is to move toward full lifecycle automation for Comcast's machine learning development pipeline.
Bridging the language gap
Data scientists tend to like to use languages like Python, while production systems run Java. To bridge this gap, Comcast has been building a set of Jython components for its data scientists.
Jython is an implementation designed to enable data scientists to run Python apps natively on Java infrastructure. It was first released in 1997 and has grown in popularity among enterprises launching machine initiatives because Python is commonly used by data scientists to build machine learning models. One limitation of this approach is that it can't take advantage of many of the features running on Flink. Jython compiles Python code to run as native Java code.
However, Java developers are required to implement bindings to take advantage of new Java methods introduced with tools like Flink.
"At some point, we want to look at doing more generation of Flink-native features," Torok said. "But on the other hand, it gives us flexibility of deployment."
Capital One ran into similar problems trying to connect Python for its data scientists and Java for its production environment to create better fraud detection algorithms. They did some work to build up a Jython library that acts as an adaptor.
"This lets us implement each feature as accessible in Python," said Jeff Sharpe, senior software engineer at Capital One.
These applications run within Flink as if they were Java code. One of the benefits of this approach is that the features can run in parallel, which is not normally possible in Jython.
Need for fallback mechanisms
Comcast's machine learning models make predictions by correlating multiple features. However, the data for some of these features is not always available at runtime, so fallback mechanisms must be implemented.
For example, Comcast has developed a set of predictive models to prioritize repair truck rolls based on a variety of features, including the number of prior calls in the last month, a measurement of degraded internet speeds and the behavior of consumer equipment. But some of this data may not be available to predict the severity of a customer problem in a timely manner, which can cause a time-out, triggering the use of a less accurate model that runs with the available data.
The initial models are created based on an assessment of historical data. However, Comcast's AI infrastructure enables engineers to feed information about the performance of machine learning in production back into the model training process to improve performance over time. The key lies in correlating predictions of the models with factors like a technician's observations.
Historical data still a challenge
Capital One is using Flink and microservices to make historical and recent data easier to use to both develop and deploy better fraud detection models.
Andrew Gao, software engineer at Capital One, said the bank's previous algorithms did not have access to all of a customer's activities. On the production side, these models needed to be able to return an answer in a reasonable amount of time.
"We want to catch fraud, but not create a poor customer experience," Gao said.
The initial project started off as one monolithic Flink application. However, Capital One ran into problems merging data from historical data sources and current streaming data, so they broke this up into several smaller microservices that helped address the problem.
This points to one of the current limitations of using stream processing for building AI apps. Stephan Ewen, chief technology officer at Data Artisans and lead developer of Flink, said that the development of Flink tooling has traditionally focused on AI and machine learning in production.
"Engineers can do model training logic using Flink, but we have not pushed for that. This is coming up more and more," he said.






