Exploring GPT-3 architecture
With 175 billion parameters, GPT-3 is one of the largest and most well-known neural networks available for natural language applications. Learn why people are so pumped about it.

OpenAI's Generative Pre-trained Transformer 3, or GPT-3, architecture represents a seminal shift in AI research and use. It is one of the largest neural networks developed to date, delivering significant improvements in natural language tools and applications. It's at the heart of ChatGPT, the large language model capable of generating realistic text, and the architecture is also integrated into a variety of enterprise apps, thanks to APIs from OpenAI and Microsoft.
Developers can use the deep learning-powered language model to develop just about anything related to language. The approach holds promise for startups developing advanced natural language processing (NLP) tools -- not only for B2C applications, but also to integrate into enterprise B2B use cases.
GPT-3 is the most popular NLP AI that is widely available, in large part because of its versatility: It can be tuned for generating code, writing sonnets, querying databases and answering customer service queries more accurately, among countless other applications. Outsiders have observed that the acronym also aptly corresponds to the term general-purpose technology, used to characterize advances like steam engines and electricity that have an impact across many industries.
GPT-3 is "arguably the biggest and best general-purpose NLP AI model out there," said Vishwastam Shukla, CTO at HackerEarth, which provides software that helps companies recruit and hire technical staff.
GPT-3 parameters
One of GPT-3's most remarkable attributes is its number of parameters.
"Parameters in machine language parlance depict skills or knowledge of the model, so the higher the number of parameters, the more skillful the model generally is," Shukla said.
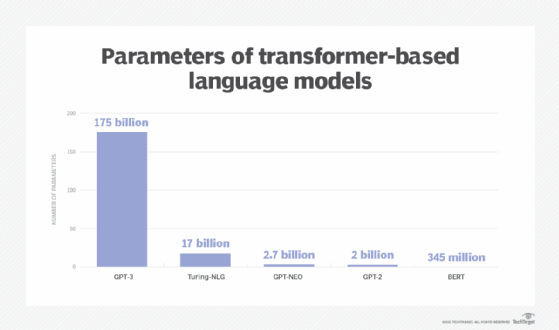
GPT-3 has 175 billion parameters, almost 2,000 times more than the number of parameters in the original GPT-1 model and over 100 times more than the 1.5 billion parameters in GPT-2.
OpenAI, the artificial intelligence research lab that created GPT-3, trained the model on over 45 terabytes of data from the internet and from books to support its 175 billion parameters.
"The AI industry is excited about GPT-3 because of the sheer flexibility that 175 billion weighted connections between parameters bring to NLP application development," said Dattaraj Rao, chief data scientist at IT consultancy Persistent Systems.
Parameters are like variables in an equation, explained Sri Megha Vujjini, a data scientist at Saggezza, a global IT consultancy.
In a basic mathematical equation, such as a + 5b = y, a and b are parameters, and y is the result. In a machine learning algorithm, these parameters correspond to the weighting between words, such as the correlation between their meaning or use together.
Performance with fewer parameters
Developers are also exploring ways to improve performance with fewer parameters. For example, EleutherAI, a collective of volunteer AI researchers, engineers and developers, released GPT-Neo 1.3B and GPT-Neo 2.7B.
Named for the number of parameters they have, the GPT-Neo models feature architecture very similar to OpenAI's GPT-2.
Rao said it gives comparable performance to GPT-2 and smaller GPT-3 models. Most importantly, developers can download it and fine-tune it with domain-specific text to generate new outcomes. As a result, Rao said he expects lots of new applications to come out of GPT-Neo.
Encoding language skills, including humor
Sreekar Krishna, principal/partner in the Digital LightHouse practice at KPMG U.S., described GPT-3 as the "next step in the evolution of a natural learning system," demonstrating that systems can learn aspects of domain knowledge and language constructs using millions of examples.
Traditional algorithmic development broke problems into fundamental core microproblems, which could be individually addressed toward the final solution. Humans solve problems in the same way, but we are aided by decades of training in common sense, general knowledge and business experience.
In the traditional machine learning training process, algorithms are shown a sample of training data and are expected to learn various capabilities to match human decision-making.
Over decades, scientists have tested the idea that if we started feeding algorithms tremendous volumes of data, the algorithms would assimilate the domain-specific data and general knowledge, language grammar constructs and human social norms. However, it was hard to test this theory, owing to limited computing power and the challenges of systematically testing highly complex systems.
Yet, the success of the GPT-3 architecture has demonstrated that researchers are on the right track, Krishna said. With enough data and the right architecture, it is possible to encode general knowledge, grammar and even humor into the network.
Training GPT-3 language models
Ingesting such huge amounts of data from diverse sources created a sort of general-purpose tool in GPT-3. "We don't need to tune it for different use cases," Saggezza's Vujjini said.
For example, the accuracy of a traditional model for translating English to German will vary based on how well it was trained and how the data is ingested. But with the GPT-3 architecture, the output seems accurate regardless of how the data is ingested. More significantly, a developer doesn't have to train it with translation examples specifically.
This makes it easy to extend GPT-3 for a broad range of use cases and language models.
"Developers can be more productive by training the GPT-3 model with a few examples, and it will develop an application in any language, such as Python, JavaScript or Rust," said Terri Sage, CTO of 1010data.
Sage has also experimented with using it to help companies analyze customer feedback to develop insight.
However, Rao argued that some domain-specific training is required to tune GPT-3 language models to get the most value in real-world applications, such as healthcare, banking and coding.
For example, training a GPT-type model on a data set of patient diagnoses by doctors based on symptoms could make it easier to recommend diagnoses. Microsoft, meanwhile, fine-tuned GPT-3 on large volumes of source code for a code autocompleter called Copilot that can automatically generate lines of source code.
Other large language models, or LLMs
Other LLMs include Beijing Academy of Artificial Intelligence's Wu Dao 2.0, with 1.75 trillion parameters; Google's Switch Transformer, with 1.6 trillion parameters; Microsoft and Nvidia's MT-NLG, with 540 billion parameters; Hugging Face's Bloom, with 176 billion parameters; and Google's LaMDA, with 137 billion parameters.
Google's Switch was designed to test techniques to efficiently support more parameters.
Wu Dao was trained to support both language processing and image recognition, using 4.9 terabytes of images and text.
Both Wu Dao and the Google Switch model used a machine learning technique known as a mixture of experts approach, which is more efficient at training models with a large number of parameters. However, these models often show performance equivalent to LLMs that are hundreds of times smaller.
GPT-3 vs. BERT
GPT-3 is often compared with Google's BERT language model, as both are large neural networks for NLP built on transformer architectures.
But there are substantial differences in terms of size, development methods and delivery models. Also, due to a strategic partnership between Microsoft and OpenAI, GPT-3 is only offered as a private service, while BERT is available as open source software.
GPT-3 performs better out of the box in new application domains than BERT, Krishna said. This means enterprises can tackle simple business problems more quickly with GPT-3 than with BERT.
But, GPT-3 can become unwieldy due to the sheer infrastructure businesses need to deploy and use it, according to HackerEarth's Shukla. Enterprises can comfortably load the largest BERT model, at 345 million parameters, on a single GPU workstation.
At 175 billion parameters in size, the largest GPT-3 models are almost 470 times the size of the largest BERT model. But GPT-3's large size comes at a much higher computational cost; this is why GPT-3 is only offered as a service, while BERT can be embedded into new applications.
BERT and GPT-3 use a transformer architecture to encode and decode a sequence of data. The encoder part creates a contextual embedding for a series of data, while the decoder uses this embedding to create a new series.
BERT has a more substantial encoder capability for generating contextual embedding from a sequence. This is useful for sentiment analysis or question answering. GPT-3, meanwhile, is stronger on the decoder part for taking in context and generating new text. This is useful for writing content, creating summaries or generating code.
Sage said GPT-3 supports significantly more use cases than BERT. GPT-3 is suitable for writing articles, reviewing legal documents, generating resumes, gaining business insights from consumer feedback and building applications. BERT is used more for voice assistance, analysis of customer reviews and some enhanced searches.





